本文是大模型训练基础课程的笔记,主要对分布式训练策略、机器学习框架和GPU作一些简单的总结。
分布式训练¶
在BERT或更早一些的RNN、CNN时代,机器学习和深度学习对算力的要求还没有现在那么高,训练一个小的模型很少会遇到算力瓶颈,随着训练数据量的增加,我们逐渐开始使用数据并行(Data Parallelism)的方式,将训练数据切分为多份,每份数据交由一台设备(比如一张显卡)来训练,每个设备保存一份模型的副本,得到各个设备上的梯度之后,通过一种方式将所有设备上的梯度进行合并计算,然后再将新的模型参数发送到每个设备上,进行新一轮的迭代;数据并行常见的方式有Parameter server和Ring AllReduce两种,前者有一台master机器用于参数管理、分发、梯度同步等操作。而后者在PyTorch中的实现即是我们常用的DDP,它利用环状通信来降低数据传输的延迟。
随着模型参数量进一步增加,当单张卡无法再容纳一个完整的模型时,就需要按照模型的层进行切分了,如对于类GPT模型,我们可以将其Embedding层即后续的多个decoder层按照时序进行切分,这种并行方式即是流水线并行(Pipeline Parallelism),流水线并行中,需要先透过前向传播,逐层向后运算,运算完毕后再由后层向前层进行反向传播,这种方式会导致部分显卡在多数时间内都是空闲状态,另外,前序设备需要保存大量的中间激活值。GPipe和PipeDream是流水线并行的两种实现。
当流水线并行切分后,单层仍无法放在单卡上时,需要对层中的张量进行切分,如对于做矩阵乘的两个矩阵$AB$来说,可以对$A$按行切分,对$B$按列切分。即张量并行(Tensor Parallelism)。
在如今的大规模语言模型训练中,一般混合使用上述三种并行方式。
机器学习框架¶
计算图、自动微分技术和GPU算力规模化称得上机器学习框架发展的几大突破,深度学习发展到现在,模型的架构暂时趋于稳定,在机器学习框架层面做研发创新的不确定性变得更高,PyTorch、Tensorflow、PaddlePaddle等几个框架占据了市场的绝大部分。现今,无论是CV、NLP还是推荐领域,Transformer架构已经逐渐成为主流,类似DeepSpeed、megatron等框架基于Transformer做了很多深度的扩展和支持,比如算子融合等,这使得框架本身逐渐“边缘化”,能做的事情也越来越有限。
自动微分技术¶
自动微分技术可以使得算法工程师无需关心其使用的算子该如何完成反向传播梯度计算,在算子的定义阶段,就需要定义好一个算子的前向计算、反向计算方法、及backward时需要的变量。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
下面是一个简单模型的前向和反向计算示例,展示了前向和反向传播的计算过程,以及计算过程中需要保存的一些中间变量。假设模型为$\hat{z}=x * W + b$,损失函数为$L=\frac{1}{2} (z-\hat{z})^2$,绘制出前向传播和反向传播图如下:
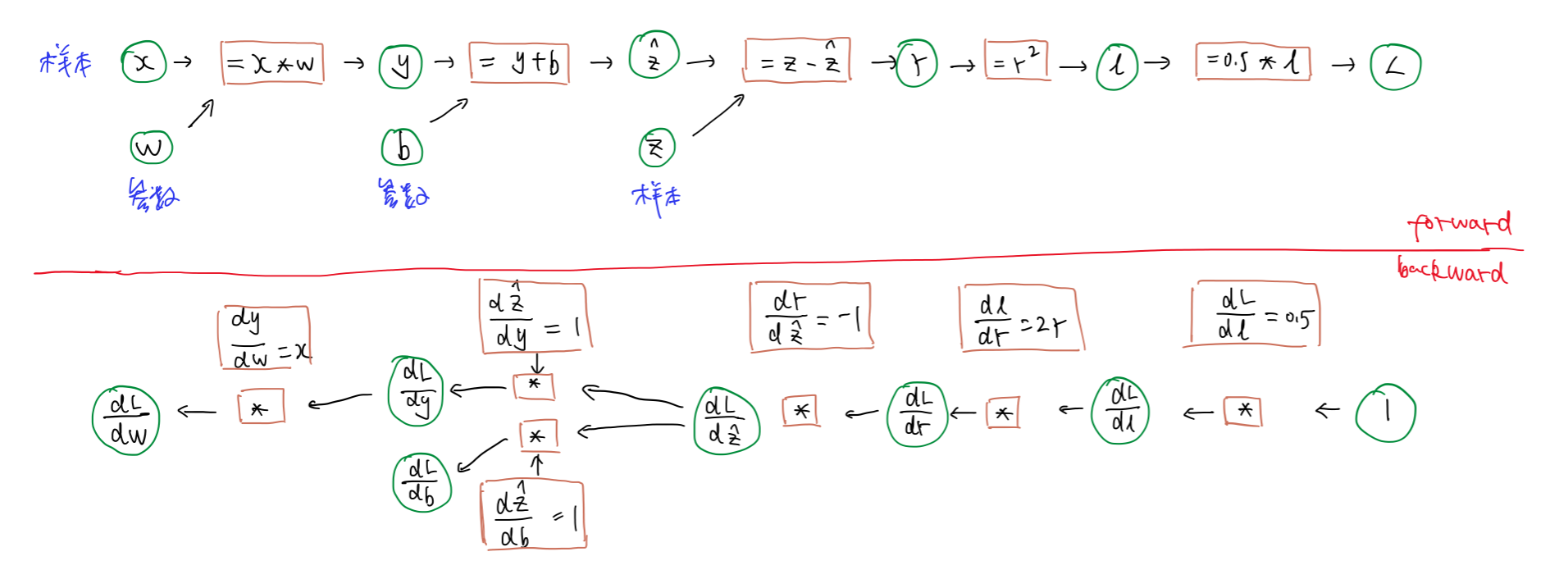
根据链式求导法则,可以得到$W$和$b$的更新公式:(假设学习率为$lr$)
$$W_{next} = W_{old} - lr * \frac{dL}{dW}$$
$$ b_{next} = b_{old} - lr * \frac{dL}{db}$$
GPU与算力¶
我们先看一下NVIDIA A100与Intel 8280(6系)的算力对比:
| NVIDIA A100 | Intel 8280(6系) | |
|---|---|---|
| Peak FP64 GEFLOPS | 19500 | 2190 |
| Memory BW GB/s | 1555 | 131 |
| Compute Intensity | 100 | 134 |
计算密度(Compute Intensity)是指在执行计算任务时,单位内存交换量(访存量)所进行的计算量。它通常用来描述计算任务的计算与内存访问需求之间的关系。计算密度可以通过下面的公式来计算:
$$ \text{Compute Intensity} = \frac{\text{Total Number of Operations(FLOPS)}}{\text{Number of Input/Output Points(Bytes)}} $$
算力密度较低时,程序访存多但计算少,整体性能受内存带宽限制,称为访存密集型程序,在此阶段,程序的性能有一个上界:计算密度*带宽;如果算力密度较大,性能逼近设备峰值性能,称为计算密集型任务。
常见的element-wise层(如ReLU)、Conv层的数据和计算都是$O(N)$的,无法通过增大数据规模的方式来提升计算密度;而矩阵乘操作,数据读取是$O(N^2)$的,而计算是$O(N^3)$的,计算密度为$O(N)$,此时,随着$N$的增大,计算密度可以逐渐提升,直至达到设备算力峰值,提升利用率。
GPU和CPU的区别¶
| NVIDIA A100 | Intel 8280(6系) | |
|---|---|---|
| Memory BW GB/s | 1555 | 131 |
| DRAM Latency(ns) (B) | 404 | 89 |
| Peak bytes per latency (C=A*B) | 628220 | 11659 |
| Threads available (D) | 221184 | 896 |
| Bytes access per Thread (Bytes) (C/D) | 3 | 13 |
| 优化重点 | 吞吐 | 延迟 |
| Compute Intensity | 100 | 134 |
| $QPS = \frac{Concurrency}{Latency}$ | 加大Concurrency | 减少latency |
上表中,Bytes access per Thread (Bytes) (C/D)是指:为了把内存打满,每一个物理线程需要发几次内存访问请求,可以发现,GPU的特点是大并发,大量Thread使得内存带宽饱和,降低计算密度要求,使算力充分发挥;而CPU设备则是降低延迟,使单个线程执行得更快,使算力充分发挥。
总结¶
本文简单回顾了DP、PP、TP三种并行、自动微分技术以及GPU与算力相关的知识。
参考¶
- 内网算法工程公开课
- 深度学习模型大小与模型推理速度的探讨