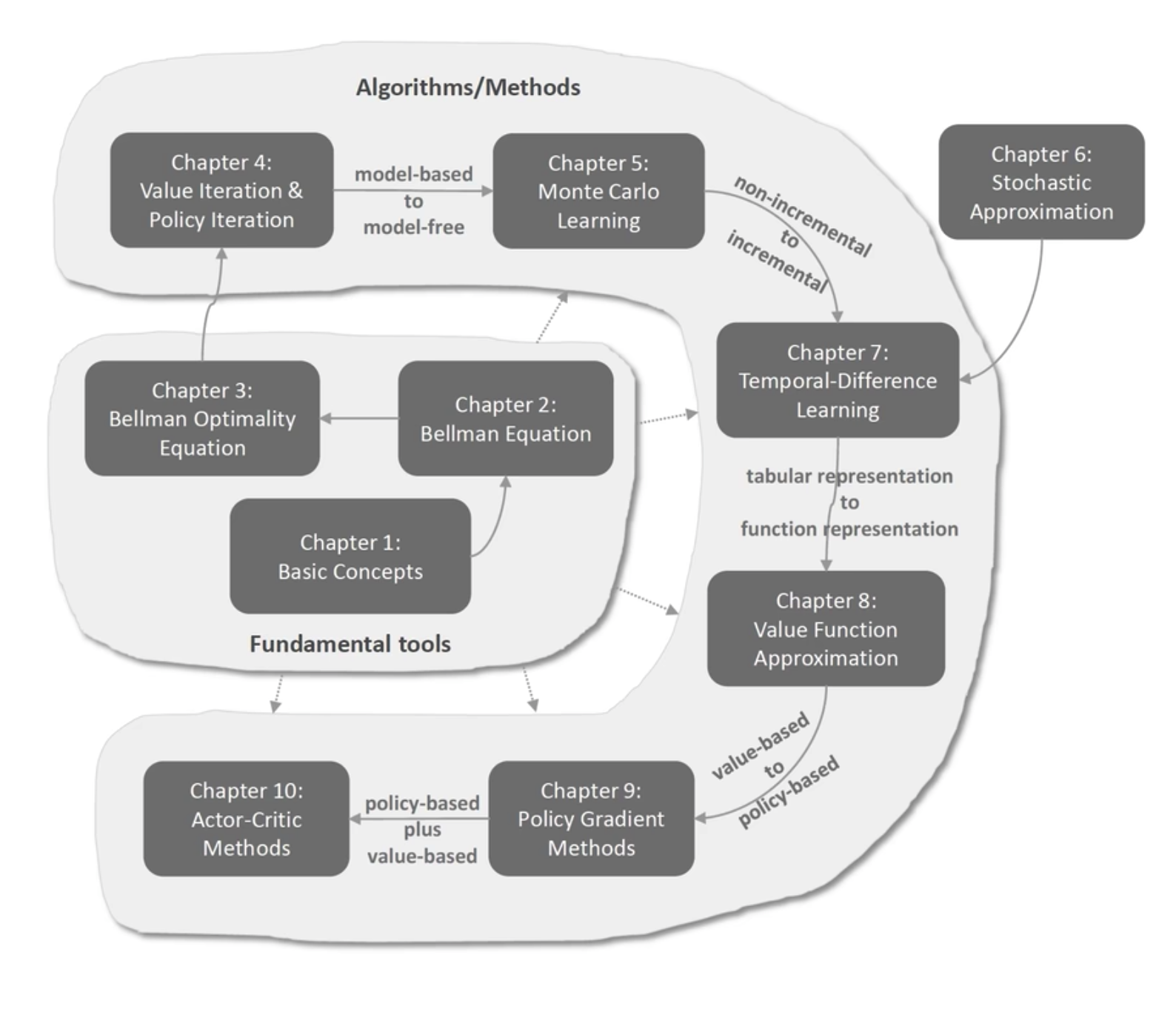
西湖大学赵世钰老师《强化学习的数学原理》笔记整理:课程介绍(P2-P3)。
这节课不涉及技术,主要讨论:
1. 为什么开这门课程¶
目前,关于强化学习有很多资料可供选择,如以下两本经典书籍:
- Sutton的“RL: An introduction”被誉为RL领域的圣经,包含高阶RL的内容,不是十分适合初学者。
- “Algorithms for RL”
还有一些控制论领域的专家写的书,理论性强,需要控制类的专业背景,不适合初学者。
RL的特点:
- 数学性强(强数学基础)
- 系统性强(环环相扣)
$$\mathrm{Math} \Rightarrow \mathrm{Intuition}$$
$$\mathrm{Math} \nLeftarrow \mathrm{Intuition}$$
本课已经在西湖大学讲授三次,书稿也已在Github上开源。本课程特点:
- 从数学地角度来理解RL的话题;
- 数学知识的深度会控制在一个level上,在可读性与专业性之间保持平衡;
- 本课程以grid-world作为示例,方便理解新概念和算法;
- 在讲解新的算法的时候,本课程力求将核心概念(core)与其复杂性(complexity)解耦,使读者抓住算法的重点;
2. AlphaGo的历史¶
- 2015年AlphaGo第一次战胜围棋2段选手;
- 2016年3月AlphaGo以4:1战胜李世石(9段)(AlphaGo输的这局是最后一次人类战胜AI);
- 2016年12月,Master(AlphaGo马甲)在中国线上创造了60:0的记录;
- 2017年5月,AlphaGo 3:0战胜柯洁;
- 2017年10月,AlphaGo Zero以100:0战胜AlphaGo(Zero不再使用人类知识,Nature: Mastering the game of go without human knowledge)
改变了很多人的想法:
- 机器可以在物理层面打败人类(飞机、汽车)
- 机器可以在智力层面打败人类(围棋)
3. RL的简史¶
RL分类:(分界线:Deep Q-Learning)
- classic RL
- deep RL
Q-Learning:广泛使用的算法,1989年一篇博士论文中被提出。被认为是一种特殊的时序差分算法(temporal-differencing algorithm, 1988年由sutton提出, 1997收敛性得到分析证明)
DP:1957年提出动态规划,用于最优控制、强化学习等。
范畴:
- AI
- ML
- Supervised Learning
- Unsupervised Learning
- RL(既不是监督学习、也不是非监督学习)
领域交叉
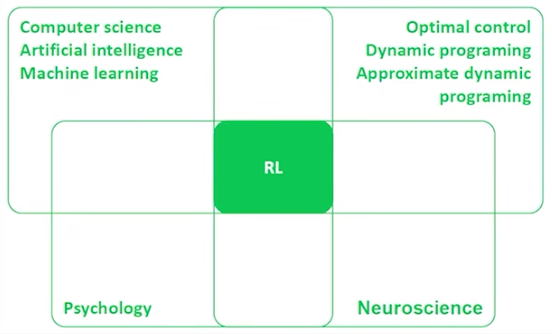
- 计算机科学(AI、ML)
- 最优控制(DP,Adaptive DP)
- 神经科学
- 心理学
4. 本课程相关细节¶
线上课程同学可跳过这部分。