西湖大学赵世钰老师《强化学习的数学原理》笔记整理:了解强化学习名词脉络(p1)。
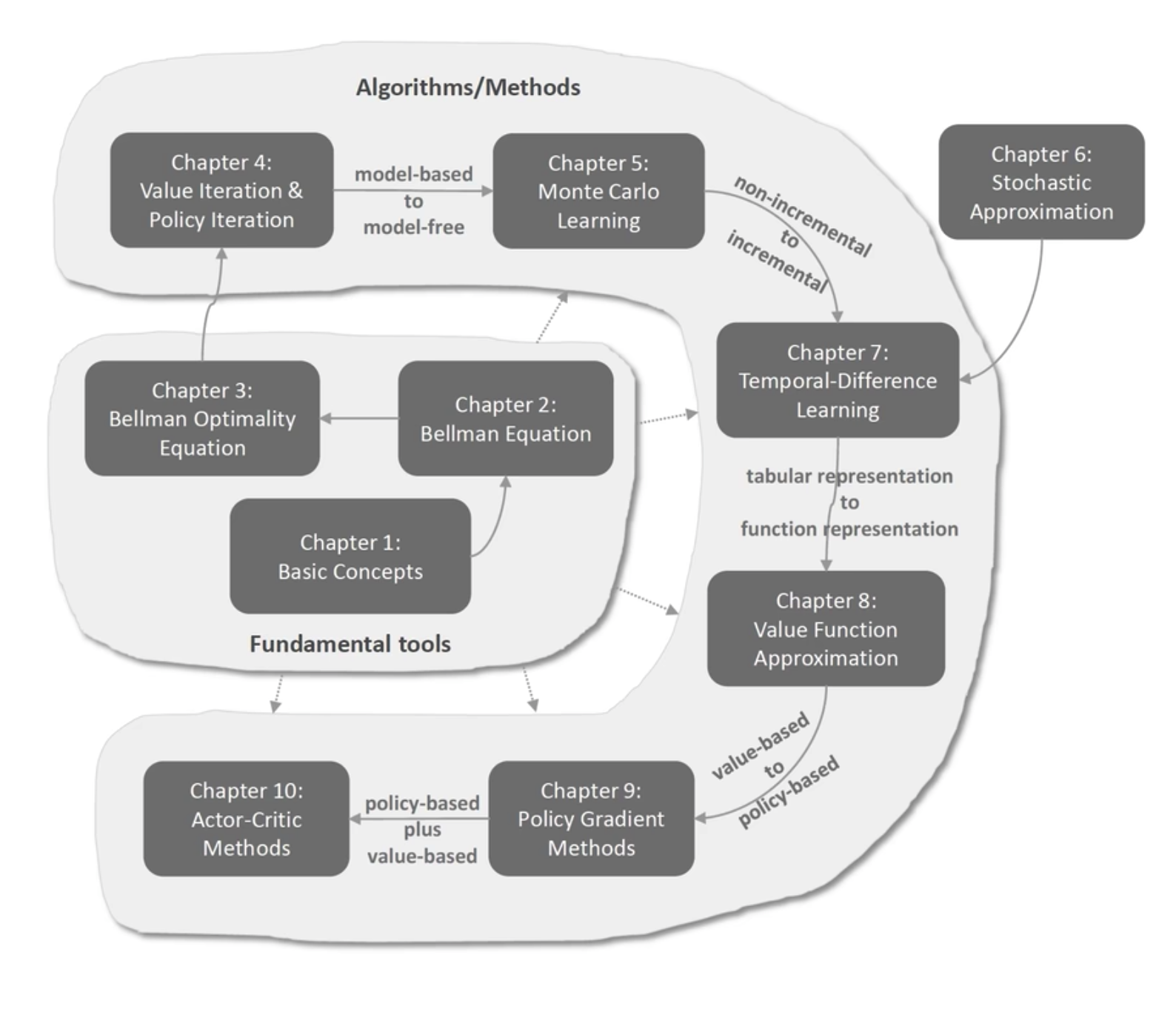
一张图概览强化学习基础原理当中的名词、概念、算法:
强化学习主要包含两个方面:原理部分、实践和编程部分,本课是关于原理部分的。建议大家放弃速成的想法,给自己的目标分配合适的时间。
强化学习的原理有两个特点:数学性比较强、系统性比较强(环环相扣);本课程11个小时左右,考虑到难点和基础知识的补齐,可能需要40个小时左右,每天4小时需要2周时间。
本课程分为两个板块:
- 基础的工具(重要体现在基础性)
- 基本的概念;贝尔曼公式;贝尔曼最优公式
- 算法和方法(重要体现在前沿性和实践性)
- 值迭代;策略迭代;蒙特卡洛的方法;时序差分的方法;基于value function approximation;policy gradient;actor-critic的方法
下面开始逐章介绍本课程概要:每一章会介绍大概两个方面:这章讲了什么样的内容、这章的内容和上下章的关系,以及在整个强化学习原理当中所处的位置以及扮演什么样的角色。
第一章 basic concepts 基本概念¶
- 强化学习中的基本概念:状态 action、reward、return、episode、policy;
- 介绍一个直观的、广泛地使用的grid-world example(网格世界)的例子(机器人在网格中找到目标区域);
- 将这些概念(正式地)放到Markov decision process(MDP)的框架下去介绍;
第二章 介绍贝尔曼公式¶
两个非常关键的点:
- 一个概念
state_value 状态值:从一个状态出发,沿着一个策略我所得到奖励回报的一个平均值,状态值越高那就说明了对应的策略越好;状态值越低那就说明了我从这个状态出发,沿着这个策略得到的奖励少,如何分析状态值?需要一个工具
- 一个工具
贝尔曼公式:(一个等式、一个方程)它描述了所有状态、状态值之间的关系,通过求解这样一个方程,能够求解出来给定策略下的状态值,这样一个过程就被称为策略评价(policy evaluation),基于该值再改进策略,然后这样循环下去,最后就能够得到一个最优的策略。这是强化学习中非常基础的一个概念。
第三章 贝尔曼最优公式¶
贝尔曼最优公式实际上是贝尔曼公式的一个特殊情况,每一个贝尔曼公式都对应了一个策略,那么贝尔曼最优公式作为特殊的贝尔曼公式,则对应着最优策略。强化学习的终极目标就是在求解最优策略。
第三章非常重要,学习要把握两点:
-
概念
最优策略(我沿着它我能够得到最大的状态值,沿着其它所有的策略得到的状态值都没它大)、最优的state value;
-
一个工具
贝尔曼最优公式,非常简洁的矩阵向量的形式。分析这个式子用到了一个不动点原理,告诉了我们这个式子两个方面的性质:
1. 最优的state value一定是存在的;最优的策略不一定是唯一的,可能是确定性的 deterministic,也可能是stochastic 随机性的;
2. 给出一个算法来求解贝尔曼最优公式,得到最优的策略和最优的state value,强化学习的目标也就达到了;其关键点就在于对于最优性的定义,它和强化学习最终的目标联系起来了。
至此前三章基础工具介绍完成。
第四章 value iteration和policy iteration¶
这个是在整个算法和方法板块当中的第一个,如果学了这个的话我们就知道了第一批能够求解最优策略的方法和算法是什么,具体来说这里我们学习了三个算法:
- value iteration 值迭代(即上述贝尔曼最有公式中,求解贝尔曼最优公式的算法:值迭代算法)
- policy iteration 策略迭代(在下一章:无需模型的蒙特卡洛方法当中会有非常重要的应用)
- truncated policy iteration(是1和2的统一化的表达形式,即1和2是3的两种极端情况)
这三个算法共同的特点是,它们都是迭代式的算法,并且在每一个迭代步骤当中都有两个子步骤,分别是policy update和value update;即,假设在当前时刻有一个不太好的策略,我们估计这个策略的值(策略评价),得到值之后我就根据这个值来改进这个策略,改进完了策略得到新的策略,再估计它的值然后再改进策略...所以有policy update和value update这两个步骤不断地迭代,最终找到最优的策略。
不仅是在第四章当中,后面所有的强化学习的算法都是在这么做的:都是在值和策略、值和策略这样不断地迭代,只不过它的具体的算法的形式可能会不同而已,这个是非常非常关键的一种思想。
另外,在这一章我们所介绍的算法是需要模型的,如果没有模型该怎么办呢?可以参考下一章。
第五章 蒙特卡洛方法¶
蒙特卡洛方法是强化学习中最早的方法,它不需要模型,而是学习随机变量的期望值,因为状态值、动作值等都是随机变量的期望值。(没有模型需要数据,没有数据需要模型,两者缺一不可。)
具体介绍了三个算法:
- MC Basic(第四章当中我所介绍的policy iteration,把里边依赖于模型的那部分给拿掉,换成依赖于数据的放进去就得到了MC Basic;实际当中不能用 因为它效率非常低)
- MC Exploring Starts
- MC $\epsilon$-greedy
它们的难度依次增加,但都基于蒙特卡洛的方法。
第六章 stochastic approximation随机近似理论¶
第五章到第七章之间存在一个比较大的鸿沟或跳跃,第五章中的算法是non-incremental的,而第七章中的算法则是incremental的。如果不熟悉这些算法,第一次看到这些算法会感到困惑。
介绍第一个问题:mean estimation,即估计一个随机变量的expectation。因为要估计$E[X]$有两种方法:non-incremental和incremental:
- non-incremental:即通过一次性求平均来得到$E[X]$的近似。
- incremental:即开始时有一个估计,得到一个采样就用这个采样来更新估计,慢慢地估计会越来越准确
具体说,本章介绍三个算法:
- Robins-Monro算法(RM算法):用于求解一个简单的函数等于0的方程,不需要知道函数的具体表达式和梯度导数;
- 随机梯度下降(SGD):在很多机器学习领域都有广泛应用;
- batch gradient descent和mini-batch gradient descent;
第七章 时序差分方法¶
时序差分方法是强化学习当中非常经典的方法。
我们介绍了用TD的方法来学习state value,这是一个比较经典的方法。在前面几章中,用蒙特卡洛方法、模型计算等方法也可以学习到state value。而这里,我们要用时序差分的方法来计算state value,这是一个与前面不同的方法。而且,这个算法可以被进一步推广到Sarsa,也就是用TD的思想来学习action value,然后得到一个新的策略再计算它的action value,不断循环下去,直到找到最优的策略。
我们还介绍了大名鼎鼎的Q-learning的算法,它直接计算optimal action value,是一个off-policy的算法。在强化学习当中,有两个非常重要的概念,一个是behavior policy,它是用来生成经验数据的,一个是target policy,这是我们的目标策略,我们不断改进希望这个target policy能够收敛到最优的策略。如果behavior policy和target policy
这两个是相同的,那么它就是on-policy;如果它们可以不同,那这个算法就是off-policy。
off-policy的好处是我们可以用之前的别的策略所生成的数据为我所用。
最后,我们给了一个统一化的视角,我们介绍了很多算法实际上表达形式都非常类似的,它们求解的数学问题也都是非常类似的。
第八章 value function approximation¶
在这一章当中,我们遇到了一个比较大的跳跃或鸿沟,从第七章到前边都是基于表格形式的,每个状态都对应一个状态值,但现在遇到的问题是,如果状态非常多或者状态是连续的,这种表格形式就不再适用了,所以要用函数的形式去进行代替。
这里介绍的第一个算法,是用value function approximation的思想来做state value estimation,具体分为三步:
- 明确目标函数;
- 求目标函数的梯度;
- 用梯度上升或梯度下降对目标函数进行优化;
其中,目标函数是真实的state value $v_{\pi}(s)$和函数值$\hat{v}$之间差的一个平均值,希望找到一个最优的$w$,使得函数能够很好地表达近似真实的$v_{\pi}(s)$。这个思想也可以和Sarsa和Q-learning相结合,估计action value,再和policy improvement相结合,不断地迭代就可以找到最优的策略。
这一章还介绍了deep Q-learning或DQN,其中包含很多技术,比如用两个网络或者经验回放等等,神经网络是函数非常好的一个表达方式,第八章首次将神经网络引入强化学习当中。
第九章 policy gradient methods¶
在第八章之前都是value-based方法,从第九章和第十章开始变成了policy-based方法,它们的区别是:第八章有目标函数$J(w)$,$w$是值函数的参数,要先更新值函数的参数,再更新策略,再估计它的值,不断找到最优的策略;而policy gradient的方法有点不一样,它是有一个目标函数$J(\theta)$,$\theta$是策略的参数,直接去优化这个$\theta$,这里我们也把策略从表格形式变成了函数的形式,即直接改变策略,慢慢地就得到最优的策略。
具体来说第九章主要介绍了policy gradient的基本思路:
1. 找到目标函数;
2. 找到对应的梯度(这个梯度叫policy gradient,policy gradient定理是直接给出来函数的梯度是什么);
3. 用梯度上升或梯度下降去优化目标函数(其中会介绍一个算法叫REINFORCE,一个非常经典的一个policy gradient的方法);
第十章 actor-critic¶
在这一章中,我们介绍了一种结合了第九章和第八章内容的算法,即actor-critic方法。它实际上是将policy-based方法和value-based方法相结合。更准确来说,actor-critic的方法实际上是第九章policy gradient的方法,叫actor-critic旨在突出value所起到的作用。
在理解actor-critic架构时,有很多直观的解释,其中我最喜欢的是用数学的式子来解释:
$$ \theta_{t+1} = \theta_{t} + \alpha \nabla_{\theta} \mathrm{ln} \pi(a_t \mid \mathcal{s}_t, \theta_{t})q_t(\mathcal{s}_t, a_t)$$
这个式子用于更新策略的参数$\theta$,通过逐渐调整$\theta$,策略会逐渐变得更好。所以,这样一个式子或算法对应的就是actor。在更新时,我们需要求出值$q$,然后根据这个值来更新策略。这就是策略和值之间的交互关系。
我们介绍了以下几种方法:
- actor-critic算法,简称QAC,实际上就是这个式子;
- advantage actor-critic算法,简称A2C,因为在其中引入了一个baseline来减小估计的方差;
- importance sampling:因为actor-critic本质上还是policy gradient,而policy gradient是一种on-policy算法,那么我们能否将其转换为off-policy呢?答案是可以的,可以使用重要性采样方法;
前面介绍的这些方法都要求策略是随机的,即在不同状态下选择所有的动作。我们也可以使用确定性的策略(deterministic),这时介绍的是deterministic actor-critic。
总结¶
本课程主要介绍强化学习的原理,而非编程实践。它更偏向于从数学的角度讲述问题,而不是从语言的描述。本课程适合那些希望深入理解强化学习原理的同学,如将来要写论文、搞研究或以此为生的人。对于只想了解强化学习基本概念的同学,学习本课程可能会感到深度超出预期。然而,教师会循序渐进地讲解数学概念,并配合大量例子,以帮助大家建立直观的概念。
在学完本课程后,下一步应该是实践。理论与实践相结合,然后再去读论文,找到自己感兴趣的方向进行深入了解。