这篇文章简单记录一下最近读的Meta的一篇的有关非参掩码语言模型的论文。这篇文章主要讨论的是类似BERT中的掩码语言模型,仅涉及encoder,不涉及decoder。
首先讨论一下BERT,BERT采用了基于token的掩码语言模型,具体地,随机地掩盖掉原句中的一些词汇,然后让模型去预测出它们,希望通过预训练过程,使模型学习到上下文的理解能力。模型的参数调整本质上也是通过“词预测”这个任务来实现的,词预测任务的目标是最大化对应token出现的概率,对于任意一个$\mathrm{[MASK]}$,经过encoder后得到的表征,通过一个映射将hidden向量映射到词表空间,在此空间上,通过$\mathrm{softmax}$计算出所有词出现的概率,并最终选择概率最大的那个作为最终的预测结果。
概率最大化是符合直觉的,但这种方式也存在一些“问题”,比如,当词库规模很大时,$\mathrm{softmax}$操作的计算还是比较耗时的;另外,对于一些罕见词,由于其在预训练过程中出现的频次较低,那么实际上在整个预训练过程中,其对应的embedding参数其实被调整的幅度相对来说并不是太大(也即,这些词的embedding并没有被充分地学习)。在这个前提下,模型对这些词汇的理解和预测能力其实是不足的。
基于上述分析,论文Nonparametric Masked Language Modeling提出了一种新的掩码语言模型——非参数掩码语言模型(NPM),首次将常规语言模型中的$\mathrm{softmax}$替换为在reference corpus中的每一个短语上的非参数概率分布,并通过batch内近似采样、构造对比学习的方式来进行预训练。实验表明这种方式相比传统的(甚至规模更大的)参数语言模型,在零样本学习任务上都有显著的提升,在低频词汇场景下的提升也更明显。
NPM模型包含一个encoder,对于包含$\mathrm{[MASK]}$的一段文本(token序列),encoder将序列中的每一个token转化为固定长度的编码向量,query对应的参考语料集转化为一个短语集合,每个短语也通过encoder获得了其对应的表征,NPM则可以根据一种相似度计算方式,从短语集合中检索出与当前$\mathrm{[MASK]}$最相近的短语,然后将其作为预测结果。
预训练¶
数据构造¶
作者在span masking的基础上作了几点改进,span的长度采样自一个几何分布。首先,如果一个query中的span同时出现在了reference corpus中,它才会被选作mask候选,其次,常规的span masking将一个span替换为一个$\mathrm{[MASK]}$,而本文中,作者将span替换为连续的两个特殊token:$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$(实际操作中,使用的是两个相同的$\mathrm{[MASK]}$,通过不同的position embedding来区分二者)。
由于实际应用中的参考语料库可能很大,语料库$\mathcal{C}$中的每一条query又包含非常多的短语(span),上文提到,语料库$\mathcal{C}$中包含的每一个span都要通过编码器获得对应的embedding,这在实际操作中对计算资源的要求比较高,为了解决这一问题,作者首先将语料库$\mathcal{C}$中的每个query通过encoder,获得其中每一个token的表征,而任意一个span的表征,则使用该span对应的起始和终止位置的token的表征拼接来表示。
至此,目标明确为,针对经过mask操作的query,对该query中的任意一对$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$,我们期望通过某种相似度计算手段,分别检索出$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$在语料库$\mathcal{C}$所包含的所有token中,最相近的那个,然后使用两个最相近的开始和结束token的位置,来圈定最终的检索答案。
目标函数¶
对于任意一个被mask的span,训练目标函数可以写为:
$$l_s(\hat{x}_t^i, g_t^i) + l_e(\hat{x}_{t+1}^i, g_t^i)$$
上述公式分别计算$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$位置的loss,作者采用对比学习方式,以$\mathrm{[MASK_s]}$为例,首先在batch内采样若干正样本和负样本,最大化正样本embedding与$\mathrm{[MASK_s]}$的embedding的相似度,同时最小化负样本embedding与$\mathrm{[MASK_s]}$的embedding的相似度。
在一个batch中假设包含两条query,如下图

其中,第一段作为被mask的query,第二段作为其reference corpus,被mask的位置是短语the Seattle Seahawks,则,对于$\mathrm{[MASK_s]}$,其正样本为the分词后的第一个token,而其余所有token所构成的span则为负样本。
inference¶
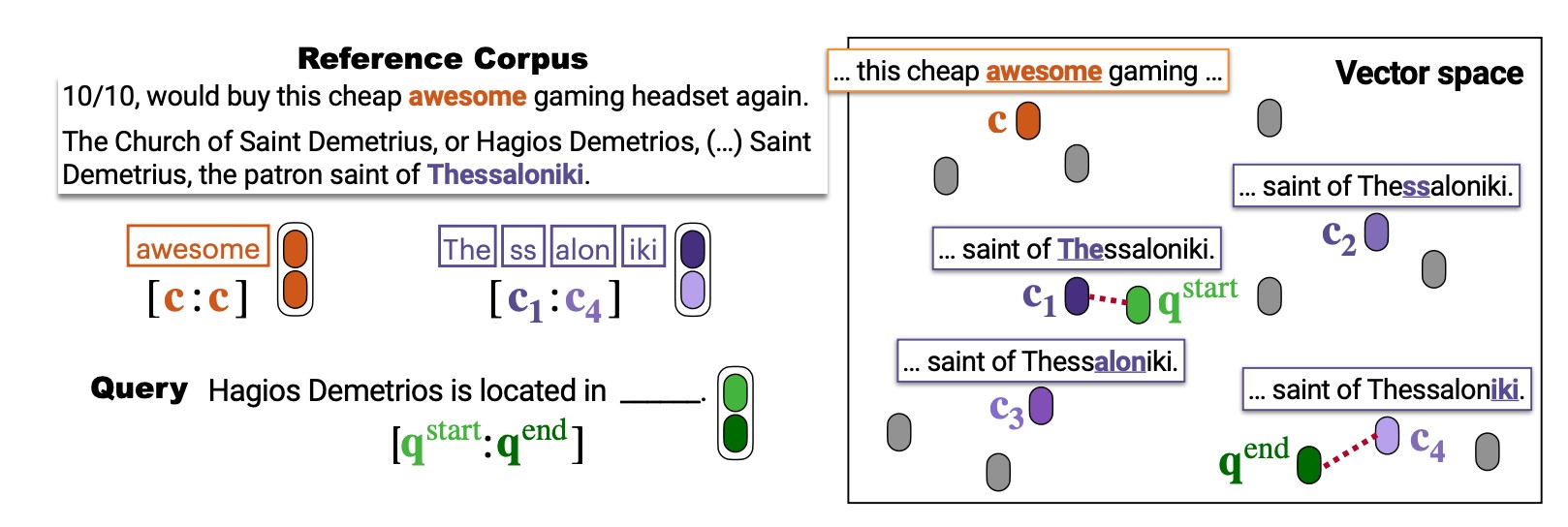
如上图,在inference阶段,reference corpus中的每一个文本均进行了tokenize操作,并且,分词后的每一个token都获得了对应的向量表征,在query中,Thessaloniki这个词被mask后,使用$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$两个token来代替,被替换后的query进入encoder,得到$\mathrm{[MASK_s]}$和$\mathrm{[MASK_e]}$分别对应的表征,接着,两个mask分别与vector space中的每一个token进行相似度计算,在预训练完成的情况下,我们预期能够得到,$\mathrm{[MASK_s]}$的表征$q^{start}$与Thessaloniki的起始位置的token:The的相似度最高,$\mathrm{[MASK_e]}$的表征$q^{end}$则与Thessaloniki的结束位置的token:iki的相似度最高。因此,被mask的位置应当检索出词汇Thessaloniki。
batch讨论¶
上文提到了在batch内部进行正负样本的采样,因此需要尽可能地保证,同一个batch内的文本的主题是相同的,否则采样时得到正样本的概率会更小,一般使用BM25这类检索工具来进行同话题文本的收集工作,但作者发现,当语料规模很大时(如百亿规模token),BM25运行的成本变得很高,因此,作者退而求其次,采用了更简单的方案,即将同一个文档进行分割,尽量使用同文档内部的作为一个batch,如果一个文档包含的文本数量不足构成一个batch时,则从其余文档中随机采样。不过比较遗憾的是,作者并未在文中讨论batch size对模型表现的影响。
总结¶
这篇文章讨论了掩码模型的非参数版,这种训练范式,在小样本场景下,本文提出的模型能够在大大节省参数的情况下,取得更优的效果,同时,这种基于类似KNN思想的检索式模型,在低频词等场景下预期也会有更好的效果。