在推荐系统、社交网络等场景中,图神经网络(Graph Neural Networks)的应用比较广泛,近年来一些GNN的变种如GCN(Graph convolutional Network)、GraphSAGE (Graph SAmple and aggreGatE)、GAT (Graph Attention Network)、GRN(Graph Recurrent Network)等在深度学习领域内逐渐引起关注,有一些模型在NLP领域也取得了不错的成绩。
卷积神经网络(CNN)或递归神经网络(RNN)可以处理规整的输入(eg., grid-like structure$^{1}$),比如对于图像,可以看做一个张量,其中任意一个元素周围总是具有相同的结构,这样我们便可以使用一个卷积核对所有位置的元素进行投影和聚合;又比如可以将文本视为一个一维的token序列,使用RNN依序对每一个token进行处理(同时考虑上文的信息)。图神经网络的一个优势在于,其可以处理非结构化的数据,比如,在一个图中的两个节点,其一度、二度、..,邻居节点的数量不相同,但GNN可以对这种结构进行特征抽取。
Transformer结构是2017年提出的一种基于自注意力的特征抽取器,目前在NLP领域应用非常广泛,基于其搭建的预训练模型也曾出不穷。
这篇文章关注图神经网络中的图自注意力网络(GAT)和Transformer在结构上的相似性。记得在前司做相关的项目时,有位大佬(此处@生哥)就曾说“BERT(当然指的是transformer了)就是GAT在全连接情况下的特例”。最近有空来梳理一下这两种结构后,不仅可以发现二者结构上的相似性,更能从“离散节点的信息融合”这个角度重新认识这两种特征抽取器。
GAT¶
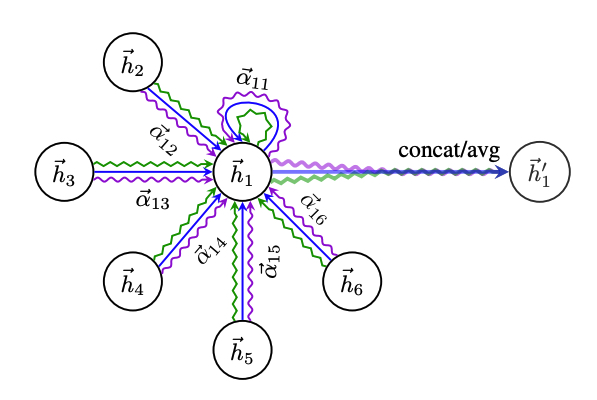
我们先看一下GAT的实现。GAT的基本单元是Graph Attention Layer,我们暂且称其为图注意力层,该层接收图上的一组节点的特征$\mathrm{h}=\\{\vec{h}_1, \vec{h}\_2 ,...,\vec{h}\_N \\}, \vec{h}\_i \in \mathbb{R}^F$,其中$N$是节点个数,$F$是节点特征向量维度。经过注意力层运算后,输出每个节点对应的新的特征:$\mathrm{h}'=\\{\vec{h'}_1, \vec{h'}\_2 ,...,\vec{h'}\_N\\}$。GAT是迭代式的,每一次迭代时,根据当前节点$i$自身的特征及其周围邻居节点的特征,通过一系列变换计算得到该节点的此轮迭代后的特征,在对其他节点的信息进行聚合时,为了考虑到不同节点的影响,GAT引入了Attention机制,具体地,对于节点$i$和节点$j$,它们之间的注意力系数可以计算为:
$$ e_{ij}=a (\textrm{W} \vec{h_i} , \textrm{W} \vec{h_j}) $$
其中,$\textrm{W} \in \mathbb{R}^{F' \times F}$是可训练的参数矩阵,$a(\cdot)$表示一种注意力机制:$a: \mathbb{R}^{F'} \times \mathbb{R}^{F'} \rightarrow \mathbb{R}$,这里作者引入了masked attention,即认为,计算注意力系数时,仅考虑节点的一阶邻居(包括该节点本身),通过这种方式保留图的结构信息。计算出节点$i$和所有邻居节点的注意力系数$e_{ij}$之后,进行一次归一化:
$$ \alpha_{ij} = \textrm{softmax}_j(e_{ij}) $$
在GAT中,作者使用一个投影层来实现$a(\cdot)$,具体地,
$$ e_{ij}= \textrm{LeakyReLU}( \vec{\textrm{a}}[ \textrm{W}\vec{h}_i \Vert \textrm{W} \vec{h}_j ]) $$
其中,$\Vert$表示向量拼接。
在得到对每个邻居节点的注意力分数$\alpha_{ij}$之后,使用其对邻居节点的特征向量进行加权,然后将所有加权结果相加。另外,作者也参考Transformer的实现,增加了多头注意力机制,多个头的输出取平均。
对每个节点执行一次这种操作,便可以得到迭代一轮后,所有节点的表征,该表征可以在下游的分类/回归问题中使用。
Transformer¶
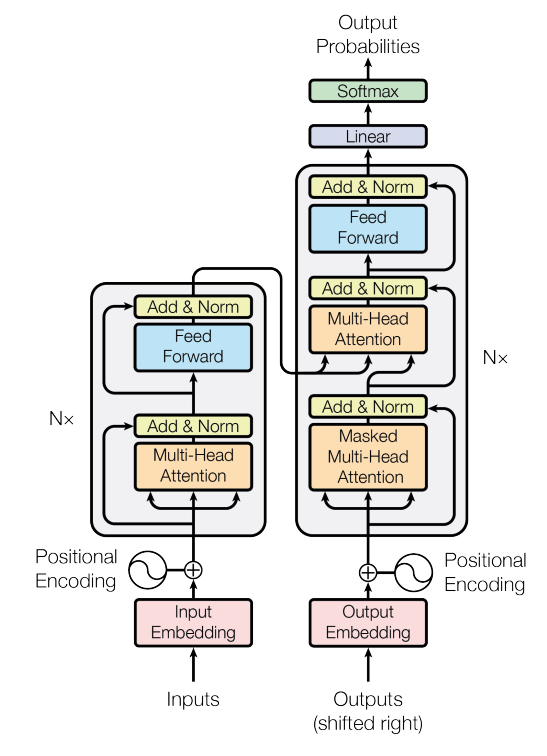
接着回顾一下transformer(以下transformer在本文特指transformer encoder layer)的结构,inputs中每一个token通过embedding lookup table获得对应的embedding后,进入transformer encoder层,transformer encoder层主要由:多头自注意力层、短路层+LayerNorm层、全连接层、短路层+LayerNorm层组成。其中,短路层可以理解为一个skip connection结构,防止过拟合;多头自注意力的结构如下:
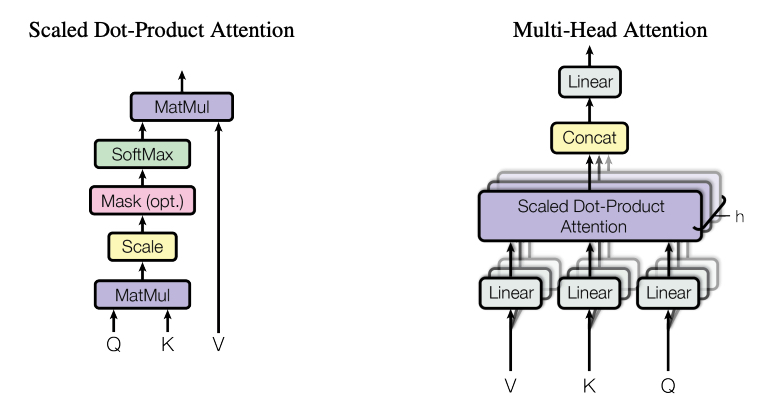
多头自注意力模块的基本单元是缩放点积注意力(Scaled Dot-Product Attention)模块,原始输入$X \in \mathbb{R}^{b\times L \times H}$将自身复制3份,命名分别作为Query,Key,Value,简记为:$Q,K,V$。其中$b$为batch_size,$L$为序列长度(序列包含的token个数),$H$表示每个token的embedding的维度。attention的计算方式为:
$$ \textrm{Attention}(Q,K,V)=\textrm{softmax}(\frac{Q^T K}{\sqrt{d_k}}) V $$
通过上述计算,序列$X$的经过自注意力机制加权后的表征变为$\textrm{Attention}(X,X,X)$。至于多头,则是首先对$Q,K,V$进行一次投影,然后分别使用多个自注意力模块计算出自注意力结果,将多个头的结果拼接后再经过一次投影,得到最终的结果。
GAT与Transformer¶
上面介绍了两个模型的基本单元:Graph attention layer和transformer,对比我们可以发现,二者的相同点如下:
- 都将输入作为一个图(其中transformer为全连接图),这里简记输入的每一个节点/token为一个node
- 模型本身均不包含/不考虑输入node的位置信息
- 均使用multi-head masked attention机制来计算node之间的相关性
- 输入与输出尺寸相同,目的都是为了获得更丰富的node表征
- 都支持多个building block的堆叠
不同点:
- transformer中包含了两次的跳远链接和LayerNorm操作,在GAT中没有
- transformer中包含一个position-wise FFN,GAT中没有
- GAT由于其稀疏图结构,其注意力计算的时间复杂度正比于边的个数,但transformer接受的输入为全连接图,复杂度与node个数$n^2$成正比
- 多头的实现方式不同:transformer是多个头的结果拼接在一起过一层投影;GAT是多个头的结果取平均
从上述异同点的对比可以看出,虽然在细节上,两个模型的实现方式存在一定的差异,但稍微抽象一下,我们可以试着以同一个角度来看二者,比如,两个模型是为了处理以图的形式存在的非结构化数据,并在此基础上引入节点之间的注意力机制来完成节点的表征的更新(迭代)。(其实transformer更像是为了无序的图结构数据而设计的,它使用较高的计算复杂度来实现任意两个节点之间的交互,只不过在用于文本处理场景时,为了引入先验的文本序列信息,才加了position embedding这个“补丁”(一家之见)。
这对我们有什么启示呢?正如博客$^4$提到的,如果两个模型的目的和设计思路是基本一致的,那二者内部的模块可以互相借鉴么?比如transformer的skip connection和scaled attention模块是否是否可以加入GAT呢?另外,对于非全连接图(即:对一段文本来说,我们引入某些token之间没有任何关系的假设),如果在transformer self-attention模块中以mask的形式引入这种先验信息,那么在这种情况下,GAT相对于transformer还会有什么优势呢?毕竟,我们可以依赖使用海量数据预训练过的transformer来引入更多的先验知识。
Refs: