近期的paper reading小结。
REBEL: Relation Extraction By End-to-end Language generation(Findings of EMNLP 21)¶
Motivation¶
关系抽取的Pipeline方式有误差传递现象,或者抽取的关系类型有限,或者无法解决“多关系”、“一头多尾”、“多头一尾”等重叠的问题;
一些seq2seq模型虽然可以通过多次生成实体的方式解决上述重叠问题,但存在暴露偏差的问题。
Contribution¶
使用自回归预训练模型(BART)以端到端生成的方式做三元组抽取。可以抽取多达200多种关系;然暴露偏差的问题仍然存在,但可以通过引入注意力机制来考虑已经解码的token,另外,作者引入了triplet linearization(用来保持三元组的顺序)。
Method¶
REBEL输入包含实体(及隐含的关系)的句子,输出一系列三元组。三元组是以一系列token的形式来生成的。模型也引入了几个特殊的token:$\lt triplet \gt, \lt subj \gt, \lt obj \gt$,其中$\lt triplet \gt$表示三元组的开始;$\lt subj \gt$表示头实体的结束,同时表示尾实体的开始;$\lt obj\gt$表示尾实体的结束,同时表示关系的开始。(在遇到下一个$\lt triplet \gt$(如有)之前,所有的三元组共享同一个$\lt subj\gt$)。举一个简单的例子:
刘德华作曲并演唱了这首《天意》。
三元组抽取序列可以表示为:
1 | |
当然,这种生成方式需要按头实体(或尾实体)将所有的三元组排序,要不然模型在预测时可能东一榔头西一棒锤地不讲武德。
最后,作者在6个数据集上评估了他们的模型(CONLL04,NYT,DocRED,ADE,Re-TACRED,REBEL)。
Qs:¶
- 解码时,如何保证结果的合理性?
- 模型的推理效率与传统的抽取模型相比如何?
- pipeline可能存在误差传递、多头多尾/多关系的情况,但联合抽取模型可以解决这些问题,本文为啥没有作对比呢?(比如TPLinker、CasRel等)
- 本文针对“抽取的关系类型有限”这一问题,但为何生成式模型可以解决这些问题呢?
Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks (Findings of EMNLP 21)¶
Motivation¶
在NLP领域,数据扩增主要有两种方式:直接修改输入token,或者从token的embedding入手,通过MLM的模块输出的在词表上的分布作为词的分布式的表征,这些替换方式面临一个问题,即替换后的token往往是一些高频词,这些词汇在一些任务上,对应的标签甚至是相反的。一些方法使用有监督的方式来做扩增,但对于样本较少的场景,这些方法的使用是受限的。
Contribution¶
作者借鉴数据扩方法mixup的思想(将两个不同的$x$/不同的$y$按照某种权重分配进行加权相加来得到新的样本),但是对同一个token,将通过MLM编码得到的分布与编码前的onehot分布进行加权融合。
Method¶
通过MLM来获得一个token(被mask掉)的表征后,与其原始onehot表征进行加权融合,作为新的表征(而标签保持不变),即:
$$t_i= \lambda \cdot t_i + (1-\lambda ) \cdot \mathrm{MLM}(t_i)$$
其中$t_i$表示某一个词的onehot表征。
作者在多个数据集上,证明了这种简单的数据扩增方法的有效性。
Qs:¶
- 修改一个样本时,如何决定哪些token要替换为这种mixup表征?
- 权重$\lambda$的影响是怎样的
Is Graph Structure Necessary for Multi-hop Question Answering?(EMNLP 20)¶
来自EMNLP 20的一篇短文,讨论了在多跳事实问答中使用图结构的必要性。结论是,在强大的预训练语言模型的加持下,图结构必要性不强。
Background: The key to solving the multi-hop question is to find the corresponding entity in the original text through the query.
Motivation¶
因为多跳事实问答中,需要考虑很多个对话轮次中的信息,因此有许多文章在这个场景中引入了图结构来对多个段落中的实体的关系进行建模。并且有文章认为,图结构对这种问题的解决是至关重要的。
Contribution¶
作者在本文中讨论了这个问题:“多跳问答中,图结构本身究竟贡献有多大?”
Method¶
作者为了回答上述问题,设计了一系列实验,对于传统模型来说,将paragraph中的实体关系以图的方式组织起来,然后将其输入GNN中,最终获得各个实体之间的表征,作者尝试将GNN模块完全去掉,即直接使用预训练语言模型对输入paragraph进行建模,对比两种方式的结果差异。从结果中发现,如果仅仅将PTM作为特征抽取器,那么GNN在整个模型中的作用是显著的,但是如果以finetune的方式引入PTM,则GNN的优势并不明显。
Unified Structure Generation for Universal Information Extraction¶
Motivation¶
目前的信息抽取任务包括实体识别、关系抽取、事件抽取、情绪识别等,下游任务之间的联系不强,需要分别进行数据构造和模型训练。
Contribution¶
本文提出了一种统一的text-to-structure生成网络,将以上信息抽取任务的形式使用schema-based prompt进行融合,构造了一种统一的生成式的信息抽取框架。在四种任务共13个数据集上验证了该方法的有效性。
Method¶
作者认为,信息抽取的任务包含两个原子操作:片段抽取和片段之间的“关系”抽取,前者称为spotting(如实体、触发词、论元等的抽取),后者称为Associating(如实体之间的关系、触发词和论元之间的关系等)。
作者首先设计了一种结构化抽取语言(SEL),将不同的信息抽取任务统一为:
1 2 3 4 5 6 | |
然后提出结构模式指示器(SSI),即一个基于模式的prompt机制,用于控制属于中哪些信息需要抽取。
Pre-training to Match for Unified Low-shot Relation Extraction¶
Motivation¶
在低资源关系抽取中,小样本和零样本关系抽取看似两种类似的任务,但实际上,对模型的要求有很大差异,小样本任务要求对support instance的表征和聚合能力(instance semantic matching);但零样本则要求模型具有标签语义匹配的能力(label semantic matching)。不同的抽取目的要求模型具有不同的结构。
Contribution¶
针对上述问题,作者提出“多选匹配网络”(Multi-Choice Matching Network,MCMN),来统一零样本和小样本关系抽取。作者认为,无论是零样本还是小样本关系抽取,都可以视作一个多项选择问题,区别在于,零样本多了一个other类来兼容NOTA类(none-of-the-above),如下图所示:
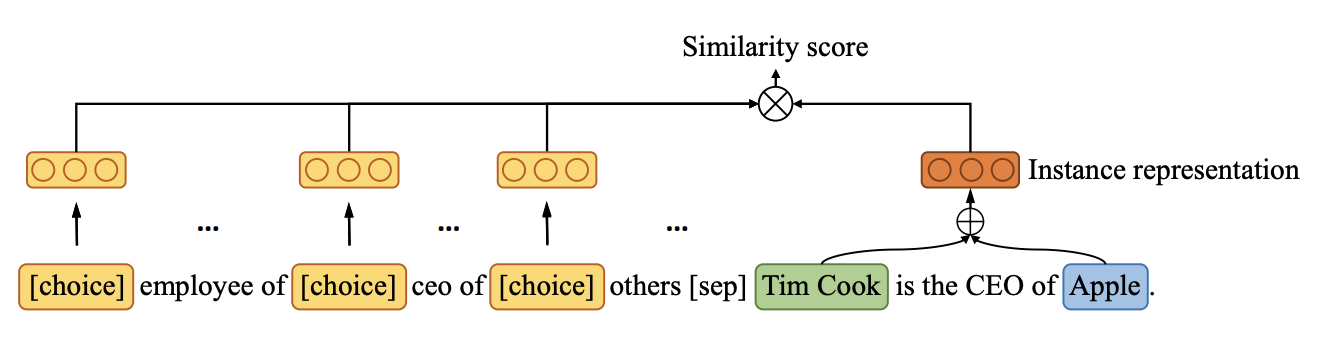
为了让模型能同时学习“标签匹配”和“样本匹配”能力,作者提出使用triplet-paraphrase元学习的框架来预训练MCMN。
Method¶
首先,作者利用开源关系抽取工具针对一批无标注数据做三元组抽取,针对任意一段文本$sentence$及其包含的某个三元组$(S,P,O)$,可以构造一条标注数据:$\texttt{[C] P1 [C] P2 ... [SEP] sentence [SEP]}$,其中,$sentence$中包含首尾实体及用于标注实体的marker,$sentence$前拼接的可以认为是一个prompt,其中包含若干个由$[C]$开头的关系描述。那么关系描述是怎么来的呢?针对一个三元组$(S_i,P_i,O_i)$,比如:$\texttt{(Jobs, CEO of, Apple)}$,作者首先加入了一些特殊的token,改写为$\texttt{[H] Jobs [R] CEO of [T] Apple}$,其中,$\texttt{[H],[R],[T]}$分别作为$(S,P,O)$的标记,然后将这个短句输入T5,生成$\texttt{Jobs is the CEO of Apple}$,将其作为三元组中包含的关系的表述(relation description)。作者用每个关系对应的$\texttt{[C]}$标签对应的hidden states与句子表征的差来作为$P$的表征:
$$D(X,p_i)=\Vert \mathrm{h}_{rel_i} - \mathrm{X} \Vert_2$$
其中,$\mathrm{X}$是句子表征,$\mathrm{h}_{rel_i}$是关系描述的hidden states。
如何应用在zero-shot和few-shot上呢?
对于zero-shot场景,使用关系名来构造prompt,如:
$$\texttt{[CLS] [C] CEO of [C] Capital of [SEP] Jobs founded Apple Inc. in 1976.}$$
对各个$D(X,p_i)$取$\mathrm{argmin}$即可得到对应的关系类别;
对于few-shot场景,需要在上述操作前增加一步online学习,即,使用support set来构造一批数据,微调一下模型(加入早停的策略来防止过拟合),然后构造与zero-shot场景类似的任务即可。
其他¶
用vscode写这篇文章时,发现我的copilot插件竟然可以帮我写博客了~

update: 2022/05/29 20:34