现实世界中的数据模态类型很多,如图像,文本,表格,模拟信号等。表示学习的任务是:针对特定的模态,自动学习到一种对数据的表示,该表示能够方便地使用数学描述和计算的同时,对数据中的高维信息进行抽象和聚合。从而尽可能减弱对特征工程的依赖。
好的表示学习可以使后续的任务更加容易,通过监督学习训练处的前馈网络可以视为一种表示学习,在学习过程中,我们并没有给中间层特征施加任何约束;表示学习算法需要在“尽可能在多地保留输入相关信息”和“追求良好的性质(如输出独立性)”之间进行权衡。
本文重点关注文本领域的表示学习,首先从通用的表示学习的角度,讨论了“好”的表示应该具有的性质;接着讨论文本表示的意义,以及近年来文本表示的方法是如何发展的;最后,对典型的文本表示的获取/训练方式作简单的介绍。
一、“好”的表示应具有的性质¶
- Smoothness: 函数光滑性是目前多数机器学习所依赖的优化算法的基础;
- Multiple explanatory factors: 真实数据是在很多潜变量的控制下生成的,找到这些潜变量或至少弄清这些潜变量的影响目标对一个好的表示学习系统很重要,探究影响真实数据的潜变量的过程,实际也是为表示增加可解释性的过程,这个过程有助于更有效的迁移学习和生成任务;
- Hierarchical representations: 表示所包含的信息应当具有一定的层次结构,使得低阶特征具有更高的可复用性;
- Share factors across tasks: 表示应能够具有一定的领域适应能力,方便在不同任务、不同模态间迁移(表示适用于多任务学习、迁移学习、领域自适应学习);
- Low dimensional manifold: 好的表示应在存在于更低维的空间(流型)中(“The better representation lies in lower dimensional manifold”),这个说法与Occam's Razor原理像是描述同一个问题的不同角度,当然,这里的“低”是有一个界限的,不可能无限制地要求表示向量存在于更低的维度,当维度到达这个界限时,表示向量能够完美的容纳样本的所有有益信息,同时不包含任何噪声,这在实际应用中是不现实的,这就要求一个好的表示学习算法能够在保留有益信息的同时,使用更有效的方式丢弃表示中包含的噪声;
- Temporal and spacial cohence: 表示向量的时空一致性,要求表示向量在时间维度和空间维度上是“连续可微分”的,举一个简单的例子,用户的购物兴趣应该随着时间的变化逐渐改变,而不是在时间维度上随意转换;
- Sparsity: 稀疏性与Low dimensional manifold相辅相成,好的稀疏性会降低模型的参数量,忽略掉无关的噪声,从另一个角度而言,假设输入为$x$。其表示为$E$,当$E$对$x$所受的微小扰动不敏感时,也可以认为这个表示具有较好的稀疏性;
- Simplicity of factor dependencies: 一个好的表示,其factor之间一定具有一些简单的关系,如线性依赖,这个假设在很多物理定理中也有所体现。也正因如此,我们在一个表示层上方接一个线性层分类器才是合理的和符合直觉的。
二、文本表示方法概览¶
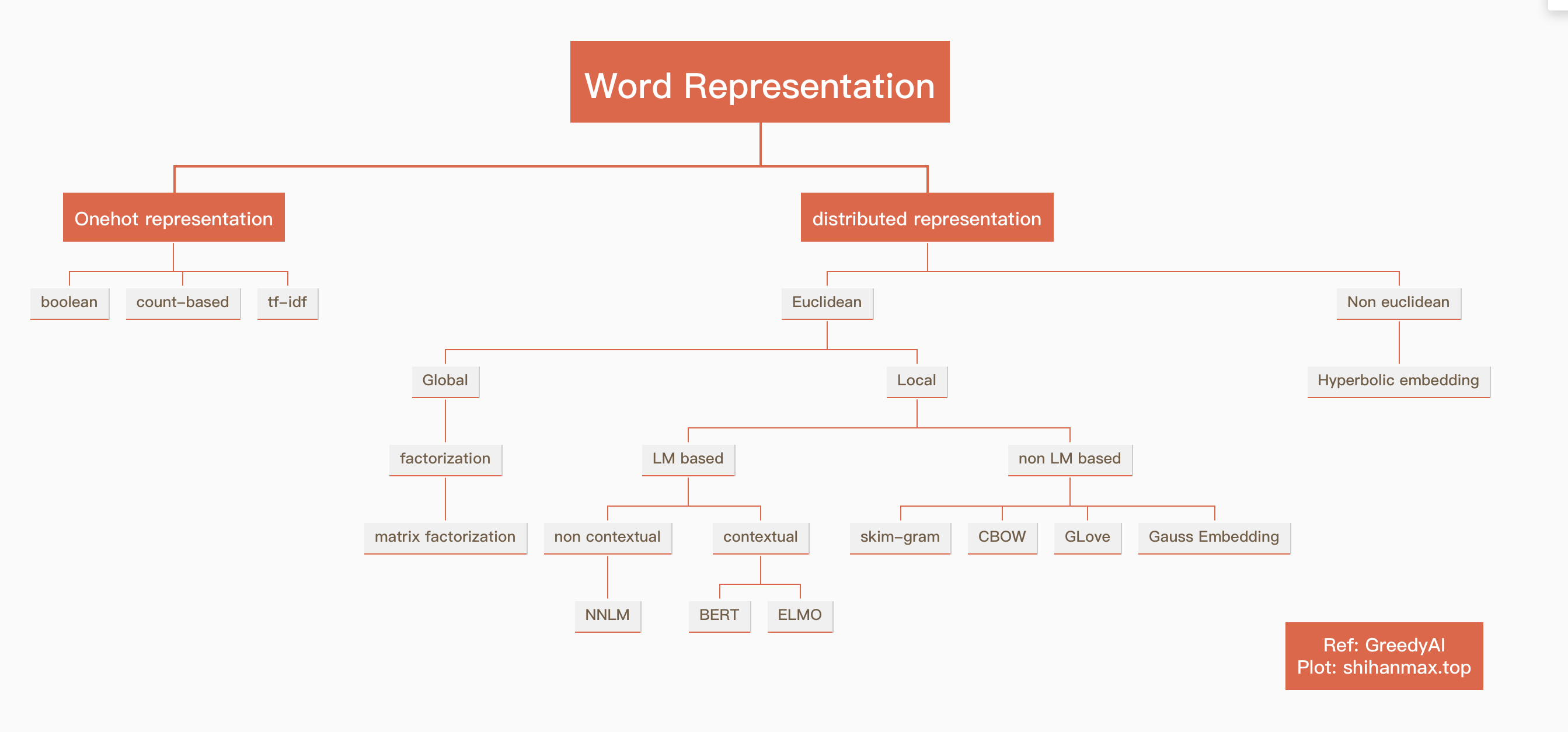
文本表示方法可以从分布形式、欧氏空间/非欧空间、全局/局部、是否基于语言模型、是否上下文相关等角度进行分类。
如我们常用的skip_gram、CBOW、Glove属于:分布式表示->欧氏空间->局部的->非语言模型的表示方法;
而Bert、ELMO等则属于:分布式表示->欧氏空间->局部的->基于语言模型的->上下文相关的表示方法。
下图是对文本表示方法的总体概括。
三、文本表示方法的演进¶
3.1 Onehot Embedding¶
Onehot embedding分为三类,它们都是基于词的出现与否/出现频次来进行词的表示的。
3.1.1 boolean embedding¶
对于文本库$C$,首先构建词表$V$,其大小为$\vert V\vert$,则一个词的boolean embedding(简记为$BE$)维度为$\vert V\vert$。
如果需要表示一个词,该词在词表中的位置为$i$,则$BE_i=1$,其余位置为$0$。
如果需要表示一个句子$W$,则针对每个词$W_j$获得其$BE_{W_j}$,然后将所有的$BE_{W_j}$进行element wise相加即可。
3.1.2 count embedding¶
Count embedding(简记为$CE$)与$BE$的表示方法的区别在于,对于一个句子,其每一个位置上不仅代表该词是否出现(是否大于$0$),而是该词在句子中出现的次数,可以看到,相对于$BE$,$CE$在句子表示中加入了单词的频次信息。
3.1.3 tf-idf embedding¶
上述两种表示形式没有区分词与词之间的重要性差异,也即,如果两个词在两个句子中的出现频次相同,那么在对应的维度上 ,这两个词的表示应当是相同的,但实际应用中,我们发现有一些词汇,其出现次数高并不能表示其在当前句子中越重要,比如一些停用词:“的”、“了”等,因为他们在绝大多数句子中出现的频率都很高。
针对这个问题,研究者提出了tf-idf权重,其本身用于描述一个单词在当前句子中的重要性。tf表示term frequency、idf表示inversed document frequency,直观理解,一个句子中,某个单词的重要程度与其在当前文档中出现的频率成正比,但与其在所有文档(文档集)中的出现频率成反比。一个词$w$的tf-idf的的计算方式如下:
$$tf-idf_{w}=tf(d,w)\cdot \log{\frac{N}{N_{w}}}$$
其中,$tf(d,w)$表示单词$w$在文档$d$中出现的频率,$N$表示文档集的大小,$N_{w}$表示出现了单词$w$的文档的个数,可以看到,当一个词出现在大多数文档中时,其逆文档频率会降低。
在使用中,可以使用一个词的tf-idf权重替换其对应位置的boolean embedding或count embedding。
3.1.4 boolean embedding小结¶
在语义计算中,很重要的一个问题是,计算两个词在其表示空间中的相似度,但遗憾的是,上文提到的boolean embedding均无法做到。因为每一个词占据表示向量的一维,词表示之间是正交的(但可以计算两个句子的boolean embedding之间的相似度);另外一个问题是,boolean embedding本质上也只是考虑了词汇的出现信息,没有考虑词或句子的语义信息;最后,由于boolean embedding的表示空间为词表的大小,而中文词表的规模在10w量级,因此会面临严重的稀疏问题。
3.2 N-Gram语言模型¶
前面聊了针对词的onehot embedding,中间插一段语言模型相关的内容:上述onehot embedding使用来表示一个词的,对于一个句子,则一般采用将句子中所有的词的表示向量相加的方式来表示,这个句子出现的概率也可以表示为句子中所有词出现的概率的乘积。这种句子表示的方式称为“词袋模型(bag of words, BOW),它不关心词之间的相对顺序,这显然是不合理的,如“我吃饭”和“饭吃我”是两种不同的场景,但词袋模型无法区分它们。基于这种考虑,我们自然想到,语言是有顺序的,当我们说出“我爱”两个字的时候,第三个字很大概率是一个名词(花草)或指代词(她)或动名词词组(吃饭),也就是后面的词是什么,部分取决于前面的的词是什么。
在自然语言处理中,文本的表示是一个问题,而“文本的评估”是另一个问题,比如计算一段话出现的概率,这个问题可以这样简单地来考虑:给定语料库$\mathcal{C}$,我们将其中的文本以句为单位切分开,得到文本集合$\mathcal{S}=\{\mathcal{s_i}, i=1,..,K\}$,那么一句话出现的概率可以表示为:
$$P_i=\cfrac{\vert \mathcal{s}_i\vert }{\vert \mathcal{S}\vert }$$
这种计算方式会面临稀疏的问题,一方面,一段话可能出现的频次较小,即分子较小,同时,语料库中包含的句子很多,分母很大,这样对绝大多数句子来说,它们的概率都很小,甚至接近$0$。这个时候可以引入N-Gram的概念。考虑一段话$\mathcal{s}$,它出现的概率可以分解为:
$$P_{\mathcal{s}}=P(w_1,w_2,\cdot\cdot\cdot,w_T)=\prod_\limits{i}^{T}{P(w_i\vert w_{i-1},w_{i-2}, ...,w_1)}$$
我们把一个句子分解为一系列词组之后,词组在整个语料库中出现的频次相较句子而言,会更高一些。
注意到,在上述概率分解中$P(w_{i}\vert w_{i-1},w_{i-2}, ...,w_{1})$表示当文本段$w_{i-1},w_{i-2}, ...,w_{1}$出现时,下一个词是$w_i$的概率。这种分解形式是一个恒等分解,所以同样会面临稀疏的问题,这时可以引入一个假设,即当前词出现的概率,仅和前面$N-1$个词有关,即仅考虑长度为$N$的窗口,这个假设也称为$N$阶马尔可夫假设,则上述概率分解式可以写为:
$$P_{\mathcal{s}}=P(w_1,w_2,\cdot\cdot\cdot,w_T) \approx \prod_\limits{i}^{T}{P(w_i\vert w_{i-1},w_{i-2}, ...,w_{i-n+1})}$$
有了这个简化,我们的统计工作会大幅简化,只要给定一个语料库,我们就可以按照上述方式,统计出小于等于窗口大小的所有词组的出现频次(及概率),这样,一段话出现的概率也就可以计算了。
当$N =1$时,这个模型退化为词袋模型。
3.3 distributed Embedding¶
针对3.1.4中提出的三个问题,研究者提出了“分布式表示”的概念,这个概念与boolean embedding的稀疏性是相对的。二者的简单对比如下:
| 表示方法 | 长度 | 元素特征 | 容量空间 |
|---|---|---|---|
| boolean embedding | $\vert V\vert$ | 个别位有值,其余为$0$ | $\vert V\vert$ |
| distributed embedding | 数百维 | 几乎每一位都有数值 | $+\infty$ |
目前,基于分布式假设的词表示模型有Word2vec和Glove两种;基于语言模型的词表示有通过NNLM、ELMO、BERT(BERT中提出了MLM和NSP任务,可以看做是一种语言模型)、XLNET等获取到的上下文相关的embedding。
3.3.1 non-LM based embedding¶
Word2vec¶
从2013年被提出到2018年BERT发布,在文本分类、序列标注、生成等众多场景中,通用领域词向量(或在数据集上继续训练)+ CNN/RNN的训练模式一直是NLP的主流,甚至目前也还有很多场景限于运算能力或任务特殊性等,还在继续使用Word2vec训练得到的词向量用来进行文本表征。
Word2vec是一种创建词嵌入(embedding)的方法$^{3}$,它假设“拥有相同上下文的词,其语义应该是相近的”,即“分布假设”。基于这个假设,我们自然有两个问题:
- 给定一个词,其上下文更有可能是什么?($?w_z?$)
- 给定一段上下文,它们中间的词可能是什么?($w_x?w_y$)
给定一个语料库,上述两个问题,都可以通过统计的方式来得到,并且预测出对应位置的词的概率分布。
Word2vec的目标是计算一个词的表示(向量),通过这个向量,我们可以计算出词与词之间的相似情况等。它的训练方式主要有两种,对应上面的两个问题,由中心词预测上下文词,由上下文预测中心词。分别称为CBOW(continuous bag of words, C-BOW)和Skip-gram,二者的模型图如下:
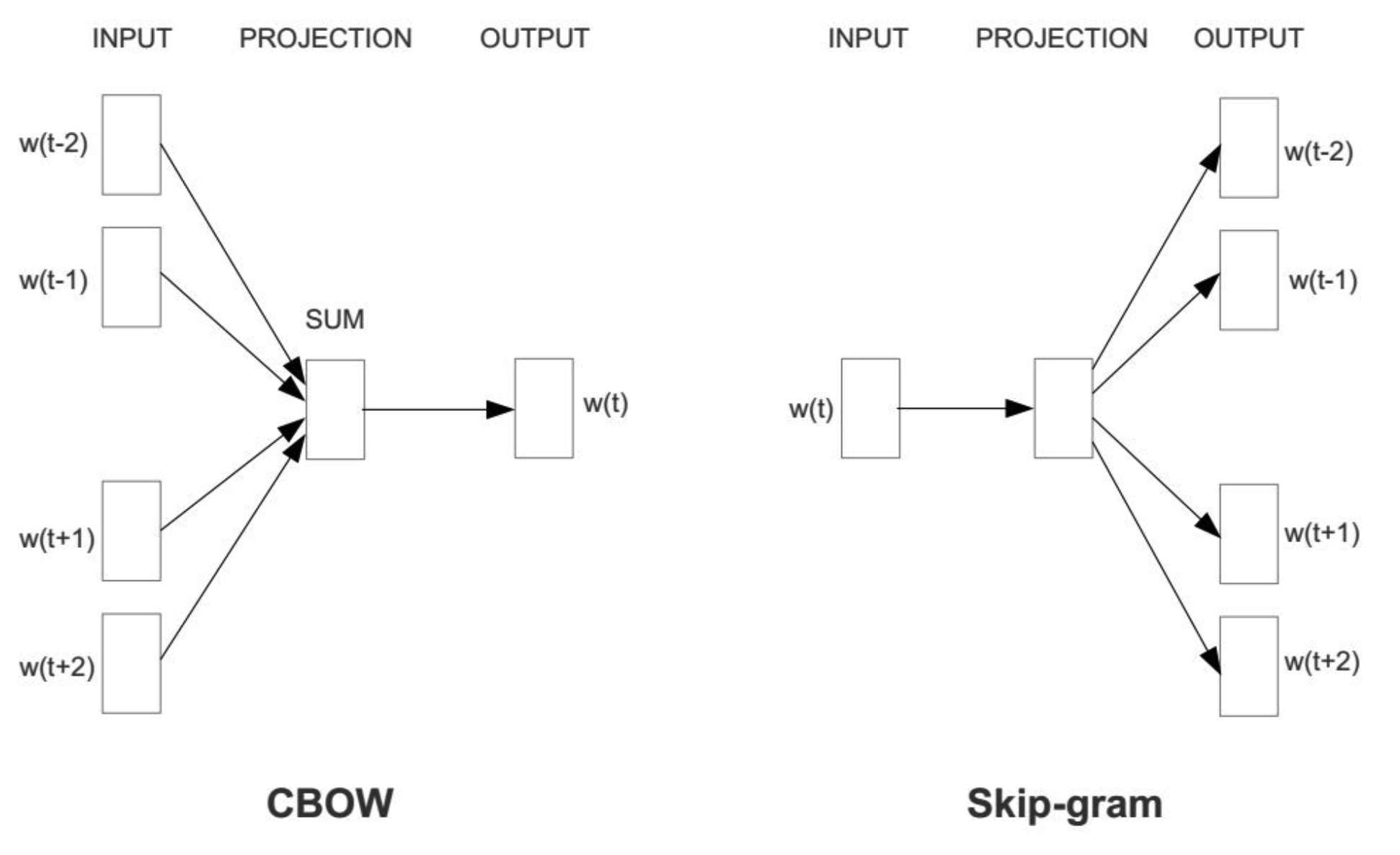
CBOW
CBOW模型使用上下文预测中心词,由上图,CBOW模型包含两个参数矩阵$W_{\vert V \vert \times N}$和$W'_{N \times \vert V \vert }$,其中$N$为词向量的维度,Word2vec的论文中设置为300。假设窗口大小为2,则输入为中心词的前两个词和后两个词,将所有单词从$0$到$\vert V \vert-1$进行编号后得到对应的onehot embedding,使用$W$分别将所有的窗口词投影到词向量空间,然后将所有的窗口词的表征相加,经过$W'$再投影回词表空间,得到一个$1\times \vert V \vert$的向量,使用$\mathbf{softmax}$可以得到预测出的中心词在词表空间中概率分布,调整交叉熵来调整两个权重矩阵,一般情况下使用$W$作为最后的词向量。
Skip-gram
Skip-gram的操作与CBOW是对称的,也包含两个参数矩阵$W_{\vert V \vert \times N}$和$W'_{N \times \vert V \vert }$,给定一个中心词,通过$W$将onehot表征投影到$N$维,然后通过$W'$投影到$\vert V \vert$维,经过$\mathbf{softmax}$后,我们将其与每一个窗口词汇计算交叉熵作为loss,来优化两个参数矩阵。
在Word2vec训练过程中,使用$W'$矩阵投影到词表空间然后进行$\mathbf{softmax}$这个操作中,$\mathbf{softmax}$需要在整个词表上进行,其计算效率比较低,针对此问题的优化方式为,使用哈夫曼树这一数据结构,将$\mathbf{softmax}$这种多分类变为在二叉树上的多级二分类,可以看作是使用参数来换计算效率的一种方式。
另外一点,我们在优化的过程中可以发现,当中心词和窗口词作为label时,它们是正样本,此时词表内其余词都是负样本,也就是说正负样本是极度不均衡的,对于这些正负样本,理论上我们都要对其参数进行更新,这个计算量是比较大的。
针对上述两个问题,Word2vec的作者在$^{3}$中提出了hierarchical softmax和negative sampling的方法,这篇论文后面有时间再详细读一下[挖坑1]。
Glove (Global Vectors for Word Representation)¶
Glove是2014年的一篇基于词共现的无监督文本表征学习模型$^5$。在Glove模型中,定义了词-词共现矩阵:
$$X_{ \vert V\vert \times \vert V \vert}$$
其中,$X_{ij}$表示词$j$在词$i$的上下文中出现的次数。对于词$i$,我们可以计算出,其余词在其上下文中出现的总次数$X_i=\sum\limits_{k}X_{ik}$,那么词$j$与词$i$的“关联程度”可以用$P_{ij}=\frac{X_{ij}}{X_i}$来表示,即词$j$是词$i$的上下文的概率。接着作者提出了“共现概率比”的概念,此时需要引入一个新的词$k$(在论文中作者称其为probe word,探针?),作者希望用若干个probe word来衡量$i$和$j$之间的关系:定义共现概率比$P_{ik}/P_{jk}$,从直觉上来看,如果词$k$与$i$更接近,那么这个比值理应特别大;如果与$j$更接近,那这个值应该非常接近0;如果这个词和两个词都很近/远,则这个比值应接近1。作者认为,使用这种比值的形式,更能区分出相近的词汇和不同的词汇。
从上述过程来看,这种训练模式得到词向量能够考虑到全局的词汇信息,因此不同于Word2vec中的两种算法,Glove是一种非LM的全局表示方法。
这篇论文和Word2vec一样非常经典,都值得详细阅读,这里不偏离本文主线,细节留到以后再学习[挖坑2]。
3.3.2 LM based embedding¶
3.3.1节讨论了分布式表征中的几种非LM的模型,下面介绍几种基于语言模型的文本表征获取方法。
NNLM
NNLM(Neural Network Language Model)$^{6}$是2003年的一篇文章中提出的基于语言模型的文本表示方法,在这篇文章中首次提出了连续的低维词向量的概念。
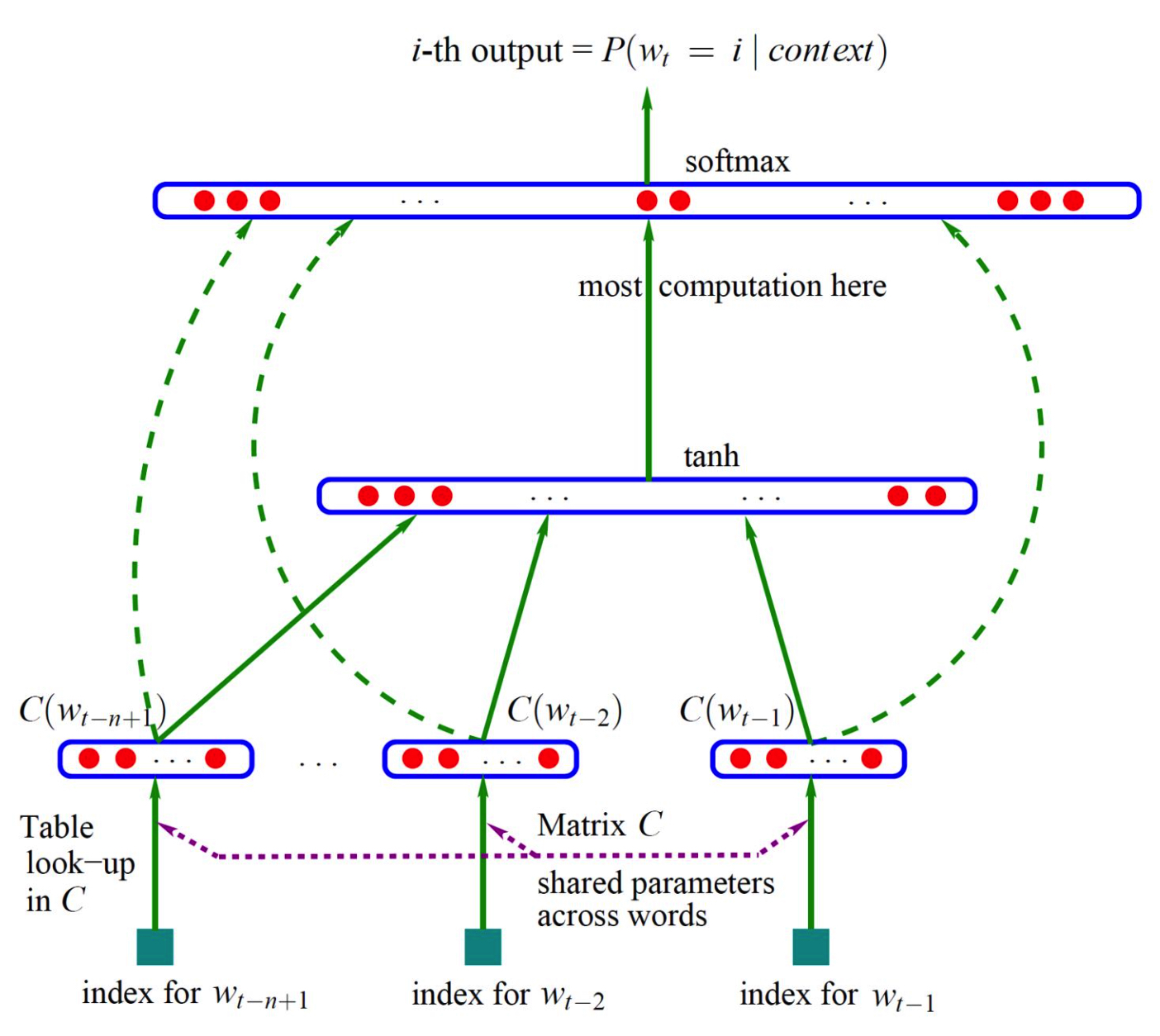
在NNLM中,同样引入了N元的语言模型假设,即一个词出现的概率仅与其前$N-1$个词有关。针对词$w_i$,其上文的$N-1$个词汇为$\{ w_{i-n+1},...,w_{i-1} \}$,使用embedding lookup table:$ C_{ \vert V \vert \times m }$来获得这些词的隐藏向量,其中,$m$为词向量的维度,$\vert V \vert$表示词库的大小,接着,将上述$N-1$个$1\times m$的表征拼接起来,得到$1 \times m \times (N-1)$的向量$c$,通过公式:
$$y=b+Wc+U\mathbf{tanh}(d+Hc)$$
将$c$投影到词表空间,其中,$W,U,H,b,d$均为参数,然后使用softmax获得对当前词的预测,使用交叉熵来计算损失,调整上述参数(参数$W$只是一个线性变换层,相当于对输入$c$的一个短路层,具体讨论可以参考原文)。
ELMo
一个词汇的embedding只能是一种吗?Apple既是水果,也是一个公司名,如何在词向量中融入这种多义的处理?又或者,同一个单词,即便代表同一个对象时,在不同的语境下,其含义应该保持不变吗?
在ELMo模型$^7$里,作者使用多层、双向LSTM来进行语言模型建模,并期望通过这种编码方式,建立对词的上下文相关的语义的表示。具体地,ELMo模型仍以无监督的方式“预测词”,由于其是双向的LSTM,其每一个方向的表征都用于预测下一个位置的token是什么,这样,一个token可以获得两个方向的表征。ELMo使用了$L$层LSTM,假设输入层的word embedding,每一个token共可以获得$2*L+1$个表征。
使用这种方式,对于同样的token,在不同语境中其表征自然会有所差别,在下有任务中,我们可以选择性地使用token的表征,比如融合所有LSTM层的输出,或者仅仅使用最后一层的。值得注意的是,虽然其使用了双向的LSTM,但本质上,仍是两个独立的LSTM分别从两个方向进行单向语言模型建模。
BERT
BERT$^8$是Google AI在2018年提出的一篇用于对文本进行预训练的论文,说BERT是一个模型不太恰当,BERT是一种预训练方法,BERT中包含(基于语言模型假设创建的)预训练任务。BERT的热度至今不减,虽然目前新的预训练语言模型层出不穷,但在预训练范式上,仍然没有跳出BERT的框架。
BERT使用Transformer的encoder作为基本的encoding单元,针对大规模无标签的语料,BERT希望能够学习到包含上下文信息的文本的embedding(contextualized word embedding),并且希望任意一个词的表征,都能够同时融合上文和下文的信息,这一点是对ELMo模型的改进。如何做到这一点?BERT提出了两个预训练的目标:MLM和NSP。MLM是掩码语言模型(另一种语言模型),它的定义是,随机遮罩一句话中的若干个位置上的词,希望能够通过剩下的词将它们预测出来,这种训练方式其实也包含了“分布假设”的意思,即一个词的概率分布是与其上下文强烈相关的,这个目标是BERT预训练方法的最重要的目标函数;另一个目标函数是NSP,其实他也是一种语言模型,这个语言模型能够对句子级别的条件概率进行估计,即在给定上一句时,这个语言模型可以判断另一个句子是否是该句的下文,当然了,后面也有一些研究对此表示了质疑,认为这个任务过于简单,并没有效果之类的,这都是后话了。
在MLM中有几点值得讨论的:
- 被掩盖的词的数量是有一个上限的,直觉上来看,如果把一个句子掩盖得面目全非,模型是很难去预测这些掩盖位置的词的,至于这个上限是多少,估计只能通过经验(实验)来估计吧,(是否还有更好的方式?);
- MLM也引入了一个不太合理的假设是,被mask掉的token之间是互相独立的,这一点的确不太符合直觉,本来是一个全局的概率估计,因为一个随机的mask操作,导致一个全连接图中的边短了几条,但这一点确实也是没有办法,每次mask一个token来训练模型,效率实在太低了;
- 当一个词以15%的概率被选中后,它仍有10%的概率保持不变,论文中提到这样做的目的是“The purpose of this is to bias the representation towards the actual observed word.”,这里其实不太清楚,为什么保持一个词不变,然后让模型预测这个词,就能够“使表征偏向被观测的词”?
自BERT提出后至今的4年时间里,有很多预训练语言模型被提出,它们的侧重点各不相同,如针对长文本的、做模型蒸馏的、针对注意力模型做计算优化的、提出新的语言模型的、增多数据增大/缩小模型结构的、针对文本生成的、轻量化推理的、知识融合的、多模态的、多语种的等等,这篇小总结自然是装不下这么多了;仔细整理一番,可能又是一个新的故事了。
Refs¶
- Representation Learning: A Review and New Perspectives
- illustrated-word2vec
- Distributed Representations of Words and Phrases and their Compositionality
- Exploiting Similarities among Languages for Machine Translation
- GloVe: Global Vectors for Word Representation
- A Neural Probabilistic Language Model
- Deep contextualized word representations
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding