关系抽取¶
关系抽取问题,可以简单描述为,给定文本段$S$,从中抽取中所有的关系三元组$(S, P, O)$,其中,$S$为subject,$O$为object,$P$为predicate。
关系抽取任务可以使用pipeline方式抽取,即先进行实体识别,再进行关系抽取。实体抽取框架可以采用softmax/CRF方式进行序列标注,也可以使用span指针法、片段排列法或MRC方式。关系分类可以通过输入两个实体的信息及二者的上下文,输出二者的关系类别。
pipeline实现简单,在实践中一般也能取得比较不错的效果,但也有一些缺点:
- 关系识别准确率受实体抽取结果的影响
- 实体抽取和关系识别两个任务之间的内在联系缺乏有效建模
- 实体抽取结果中存在一些冗余实体(即这些实体和其他实体之间不存在关系)
近年来,一些联合抽取的方法不断涌现,端到端抽取效果也在不断刷新记录。本文以联合抽取为背景,简单梳理一下从NovelTagging开始,几篇比较典型的联合抽取论文的实现思路。在开始之前,首先讨论一下实际的关系抽取任务中存在的几种稍微复杂的场景。
关系抽取中的几种复杂情况¶
-
SEO (single entity overlapping)
如句子"《热河》和《大象》是李志的两首代表作。"中,"李志"同时作为三元组
(李志, 作品, 《热河》)、(李志, 作品, 《大象》)的subject,即两个三元组之间存在一个实体重叠的情况;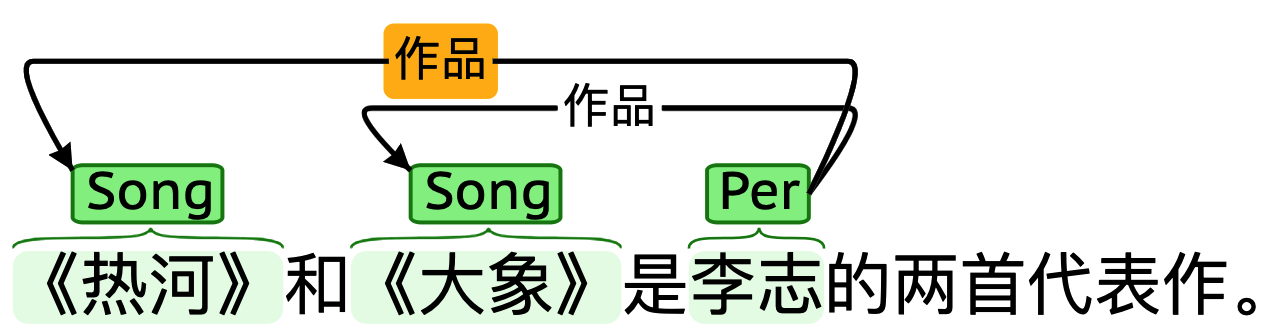
-
EPO (entity pair overlapping)
如"《鸵鸟》是由李志作词作曲并演唱的一首歌曲。"中,subject"李志"与object"《鸵鸟》"之间有四种关系:"作词"、"作曲"、"演唱"、"作品",即三元组之间共享头尾实体的情况;

典型的E2E抽取框架介绍¶
NovelTagging¶
NovelTagging是一种早期的联合抽取方法,它将联合抽取任务转化为序列标注问题。与传统的Pipeline方法不同,NovelTagging直接通过一个端到端的模型同时完成实体识别和关系抽取任务。该方法的核心思想是设计一种新颖的标注方案,使得实体和关系可以在同一个标注序列中被识别出来。
NovelTagging的主要贡献在于:
1. 提出了一种新的标注方案,将实体识别和关系抽取统一为序列标注任务
2. 设计了端到端的神经网络模型,能够同时处理实体和关系的联合抽取
3. 通过共享参数和联合优化,增强了实体识别和关系抽取之间的交互
该方法通过LSTM等序列模型来编码输入文本,然后使用CRF层进行解码,直接输出包含实体和关系信息的标注序列。相比Pipeline方法,NovelTagging能够更好地利用实体和关系之间的关联信息,从而提高整体的抽取性能。
模型结构:
NovelTagging的模型结构包括:
1. 词嵌入层:将输入文本转换为词向量表示
2. BiLSTM层:捕获文本的上下文信息
3. CRF层:进行序列标注,输出实体和关系标签
训练阶段:
训练目标是最小化标注序列的负对数似然损失:
$$\mathcal{L} = -\log P(Y|X)$$
其中$X$是输入文本,$Y$是对应的标签序列。
推理阶段:
在推理阶段,模型通过维特比算法解码出最优的标签序列:
$$Y^* = \arg\max_Y P(Y|X)$$
然后根据标签序列提取出所有的三元组。
CopyR¶
CopyR是一种基于序列到序列(Seq2Seq)框架的联合抽取模型,它借鉴了机器翻译和文本摘要中的Copy机制。该模型将关系抽取任务看作是从输入文本生成关系三元组的生成式任务。
CopyR的主要特点包括:
1. 使用编码器-解码器架构,其中编码器对输入句子进行编码,解码器生成三元组
2. 引入Copy机制,允许解码器直接从输入文本中复制实体,避免生成不存在的实体
3. 通过注意力机制建立输入文本和输出三元组之间的对齐关系
在CopyR中,解码过程按照关系、头实体、尾实体的顺序依次生成三元组的各个组成部分。该方法能够自然地处理重叠关系问题,因为生成过程不受预定义实体对的限制。同时,Copy机制保证了生成的实体词汇一定出现在原文本中,提高了抽取结果的准确性。
模型结构:
CopyR的模型结构包括:
1. 编码器:BiLSTM网络,将输入句子编码为隐藏状态序列
2. 解码器:LSTM网络,逐步生成三元组
3. 注意力机制:计算输入序列与当前解码状态的对齐权重
4. Copy机制:允许从输入中直接复制词汇
训练阶段:
训练目标是最小化生成三元组的负对数似然损失:
$$\mathcal{L} = -\sum_{t=1}^{T} \log P(y_t|y_{ 其中$X$是输入文本,$y_t$是第$t$个生成的词。 推理阶段: $$Y^* = \arg\max_Y P(Y|X)$$ 解码过程遵循"关系→头实体→尾实体"的顺序,逐步生成完整的三元组。 GraphRel是一种基于图卷积网络(GCN)的联合抽取模型,它将文本建模为关系图,通过图神经网络来捕捉实体和关系之间的复杂交互。 GraphRel的核心思想包括: 该模型的主要优势在于: 模型结构: GraphRel的模型结构包括两个阶段: 训练阶段: $$\mathcal{L} = \mathcal{L}_{entity} + \mathcal{L}_{relation}$$ 其中实体损失$\mathcal{L}_{entity}$是标准的序列标注损失,关系损失$\mathcal{L}_{relation}$是多分类交叉熵损失。 推理阶段: 最终的三元组通过实体对之间的关系得分确定。 RSAN(Relation-Specific Attention Network)是一种基于关系特定注意力机制的联合抽取模型。该模型的核心思想是为每种关系构建特定的句子表示,然后基于这些表示进行序列标注来提取对应的实体对。 RSAN的主要创新点包括: 在RSAN中,首先使用BERT等预训练模型对输入文本进行编码,然后针对每种关系计算相应的注意力权重。这些权重用于构建关系特定的句子表示,使得模型能够关注与当前关系最相关的文本片段。接着,基于这些表示进行序列标注,识别出与该关系相关的实体对。 该方法的优势在于能够为不同关系建模不同的语义模式,提高了关系抽取的准确性。同时,通过注意力机制能够自动识别与关系相关的关键词汇,增强了模型的可解释性。 模型结构: RSAN的模型结构包括: 训练阶段: $$\mathcal{L} = -\sum_{r \in R} \log P(Y^r|X, r)$$ 其中$R$是关系集合,$Y^r$是在关系$r$下的实体标签序列。 推理阶段: CasRel是发表在ACL2020上的一篇联合抽取模型,整体结构比较简洁,抽取过程如下:
在推理阶段,模型通过束搜索(beam search)生成三元组:GraphRel¶
1. 构建文本的关系图表示,其中节点代表单词,边代表词语之间的依赖关系
2. 使用图卷积网络对图结构进行编码,捕获长距离依赖和复杂语义关系
3. 设计两阶段的抽取过程:首先识别实体,然后基于实体信息抽取关系
- 能够有效建模文本中的复杂依赖关系,特别是长距离依赖
- 通过图结构更好地捕捉实体和关系之间的交互信息
- 在处理重叠关系和复杂语义场景时表现良好
1. 第一阶段:使用BiLSTM和GCN提取顺序和依赖特征,预测实体和关系
2. 第二阶段:基于第一阶段的预测结果构建关系加权图,使用关系加权GCN进一步优化特征表示
训练目标包括实体损失和关系损失:
推理过程分两阶段进行:
1. 第一阶段:预测实体和关系
2. 第二阶段:基于关系加权图优化预测结果RSAN¶
1. 引入关系特定的注意力机制,为每种关系构建专门的句子表示
2. 通过注意力权重突出显示与特定关系相关的词汇和短语
3. 使用序列标注的方式同时抽取实体和关系
1. BiLSTM层:编码输入文本的上下文信息
2. 关系特定注意力机制:为每种关系计算注意力权重
3. 关系门控机制:自适应控制关系信息的传递
4. 实体解码器:基于关系特定表示进行序列标注
训练目标是最小化实体标注的负对数似然损失:
推理过程为每种关系分别进行实体抽取:
1. 对于每种关系$r$,计算关系特定的句子表示
2. 基于该表示进行序列标注,识别实体对
3. 组合所有关系下的实体对形成最终的三元组集合CasRel¶
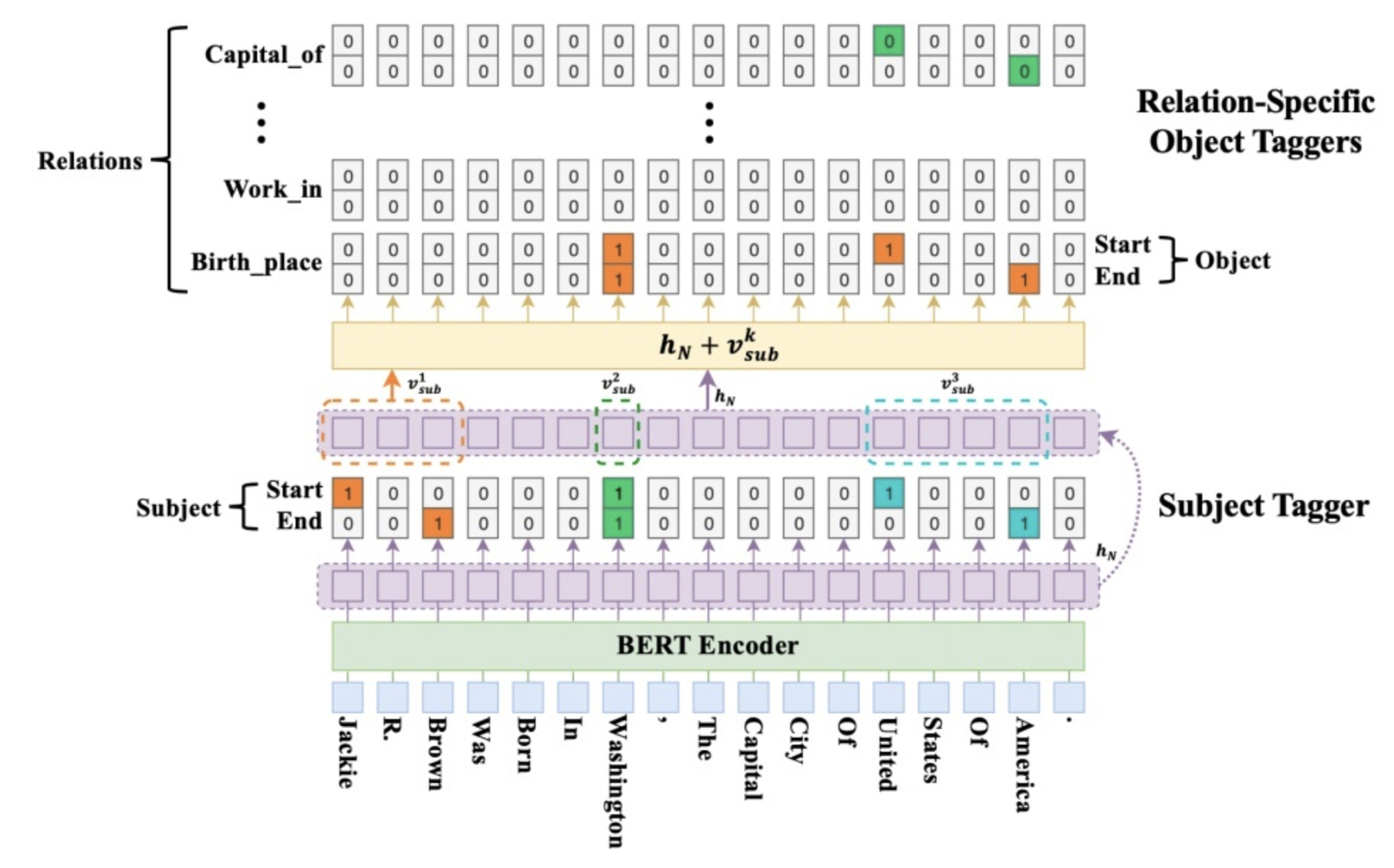
-
文本经过BERT Encoder获得每个token对应的表征$R_{L*H}$;
-
$R_{L*H}$通过一个span NER层(Subject Tagger,ST),ST包含两个参数矩阵:$W_{start}$,$W_{end}$,维度均为$H * 1$。文本表征经过这两个参数投影后,所有的头实体(subject)的首尾位置都被抽取出来。从start结果开始解码,当某位为1时,表示为实体开头,接着从对应位置开始,去end结果中向后寻找该实体对应的结尾,至此抽取到了所有的subject:$\{S_1,S_2,...,S_K \}$;
-
假设共有$R$种关系,对关系$r$,包含object投影矩阵$W^r_{start}$和$W^r_{end}$,维度均为$H*1$,针对每一个subject $S_k$和关系$r$,定义$p_i^{start\_o}$、$p_i^{end\_o}$分别为"给定subject $S_k$和关系$r$时,$token_i$为对应的object起始和结束位置的概率":
$$p_i^{start\_o}=\sigma(\mathrm{W}^r_{start}(\mathrm{x}_i+\mathrm{v}^k_{sub}+\mathrm{b}^r_{start}))$$
$$p_i^{end\_o}=\sigma(\mathrm{W}^r_{end}(\mathrm{x}_i+\mathrm{v}^k_{sub}+\mathrm{b}^r_{end}))$$
则对每一个subject $S_k$,可以解码得到其在每一种关系下可能的候选object。
注意,与subject的span计算方式不同之处在于,解码object时,同时会将对应的subject表征融入token表征中,从公式中可以看到,对于每一个token,融合结果是原有bert encoding与subject $S_k$的表征$\mathrm{v}^k_{sub}$进行加和,而$\mathrm{v}^k_{sub}$则是实体$S_k$中所有token的表征通过avg pooling得到的;
- object的解码方式与subject类似,至此,可以抽取出所有subject在所有关系下的可能的object;
训练阶段:
CasRel的训练目标包括subject标注损失和object标注损失:
$$\mathcal{L} = \mathcal{L}_{subject} + \sum_{k=1}^{K} \sum_{r=1}^{R} \mathcal{L}_{object}^{k,r}$$
其中$\mathcal{L}_{subject}$是subject实体的二分类交叉熵损失,$\mathcal{L}_{object}^{k,r}$是在给定第$k$个subject和第$r$种关系条件下object实体的二分类交叉熵损失。
推理阶段:
推理过程按照以下步骤进行:
1. 使用subject tagger识别所有subject实体
2. 对每个识别出的subject和每种关系,使用object tagger识别对应的object实体
3. 组合所有(subject, relation, object)三元组
算法伪代码:
1 2 3 4 5 6 7 8 9 10 11 | |
TPLinker¶
TPLinker来自COLING 2020,在本文中,作者设计了一种新颖的数据构造和训练方式。可以实现对重叠关系和重叠实体的联合抽取。
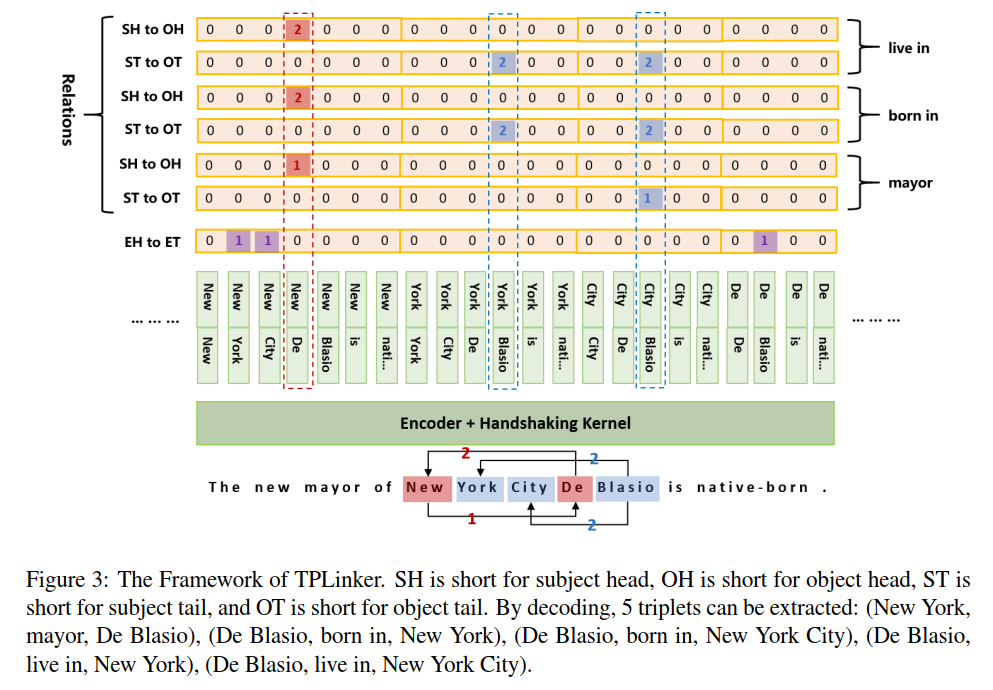
首先看一下作者对数据的定义方式:在TPLinker框架中,有三个状态矩阵:
- EH-ET(entity head to entity tail):$L\times L$
- SH-OH(subject head to object head):$R \times L\times L$
- ST-OT(subject tail to object tail):$R \times L\times L$
其中,第一个负责实体的识别,剩余两个负责首尾实体的链接(linking)。
则,对于长度为$L$的文本中的某一个三元组$(S_{i,j},P_{k},O_{m,n})$,有:
- $EH-ET[i,j] = 1$,$EH-ET[m,n]=1$
- $SH-OH[k,i,m]=1$
- $ST-OT[k,j,n]=1$
其中,$S$和$O$分别为subject和object,$X_{a,b}$表示实体$X$的开始和结束下标分别为$a,b$;$P$为predicate,即实体之间的关系。
上述共有$2R+1$个$L\times L$的矩阵,分别表示长度为$L$的文本中任意两个token之间的关系,为了节省计算量,可以将下三角位置的所有的$1$沿主对角线翻转复制到上三角中,并将值修改为$2$(以与上三角阵中的$1$进行区分)。
按照上述方式构造训练数据,使用BCE即可对参数进行调整。下面着重记录一下TPLinker的解码方式。
首先,通过$EH-ET$矩阵,解码出所有的实体,对于上图中的例子,可以解码得到三个实体,我们以实体的开始位置下标为key,将所有实体保存到字典中:{4: ["New York", "New York City"], 7: ["De Blasio"]}
训练阶段:
TPLinker的训练目标是最小化所有矩阵的二分类交叉熵损失:
$$\mathcal{L} = \mathcal{L}_{EH-ET} + \sum_{r=1}^{R} (\mathcal{L}_{SH-OH}^r + \mathcal{L}_{ST-OT}^r)$$
其中每一项都是标准的二分类交叉熵损失。
推理阶段:
推理过程分三步进行:
1. 使用$EH-ET$矩阵识别所有实体
2. 使用$SH-OH$和$ST-OT$矩阵链接实体对
3. 根据关系类型组合实体对形成三元组
算法伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
TDEER¶
TDEER(Translating Decoding Schema for Joint Extraction of Entities and Relations)是一种基于翻译解码机制的联合抽取模型。该模型将关系抽取任务视为一种翻译过程,即给定主体实体和关系,"翻译"得到对应的客体实体。
TDEER的主要特点包括:
-
采用翻译解码机制:
- 将三元组建模为"主体 + 关系 → 客体"的形式
- 通过这种翻译机制自然地处理重叠三元组问题
- 能够识别所有可能的三元组,包括重叠和非重叠情形 -
三阶段解码过程:
- 第一阶段:使用基于跨度的实体标记模型提取所有主体实体和客体实体
- 第二阶段:采用多标签分类策略检测所有可能的关系
- 第三阶段:基于翻译机制将主体实体和关系映射到对应的客体实体 -
模型优化:
- 引入负样本以增强模型鲁棒性
- 缓解不同阶段中误差的累积问题
- 在计算效率方面表现优异,推理速度比近期SOTA模型快约两倍
TDEER的核心思想是将关系抽取任务类比为机器翻译任务,其中主体实体和关系的组合作为源语言,客体实体作为目标语言。模型通过学习这种"翻译"关系来完成三元组的抽取,这种设计使得模型能够更好地捕捉实体和关系之间的语义关联。
模型结构:
TDEER的模型结构包括三个主要组件:
1. 实体抽取器:基于跨度的模型识别所有实体
2. 关系分类器:多标签分类器检测句子中的关系
3. 翻译解码器:基于主体实体和关系生成客体实体
训练阶段:
TDEER的训练分为三个阶段:
1. 实体抽取损失:$\mathcal{L}_{entity} = -\sum_{i=1}^{n} \log P(e_i|X)$
2. 关系分类损失:$\mathcal{L}_{relation} = -\sum_{j=1}^{m} \log P(r_j|X)$
3. 翻译解码损失:$\mathcal{L}_{translate} = -\sum_{k=1}^{p} \log P(o_k|s_k, r_k, X)$
总损失为:$\mathcal{L} = \mathcal{L}_{entity} + \mathcal{L}_{relation} + \mathcal{L}_{translate}$
推理阶段:
推理过程按照以下步骤进行:
1. 使用实体抽取器识别所有实体
2. 使用关系分类器检测句子中的关系
3. 对每个(主体,关系)对,使用翻译解码器生成客体实体
4. 组合形成完整的三元组
算法伪代码:
1 2 3 4 5 6 7 8 9 10 11 | |
SDN¶
SDN(Sparse Dilated Network)是一种基于稀疏膨胀网络的联合抽取模型。该模型通过设计特殊的网络结构来捕获文本中的长距离依赖关系,同时保持计算效率。
SDN的主要创新点包括:
-
稀疏膨胀卷积:
- 采用膨胀卷积(Dilated Convolution)来扩大感受野,捕获长距离依赖
- 通过稀疏化设计减少参数量和计算复杂度
- 能够在不增加网络深度的情况下获得更大的上下文信息 -
多尺度特征融合:
- 设计多层膨胀卷积,捕获不同尺度的文本特征
- 通过特征融合机制整合多尺度信息,提高模型表达能力 -
联合解码策略:
- 设计统一的解码层同时处理实体识别和关系抽取
- 通过参数共享和联合优化增强两个任务之间的交互
SDN的优势在于能够在保持较高准确率的同时显著降低计算成本,特别适用于处理长文本的实体关系抽取任务。稀疏膨胀卷积的设计使得模型能够有效捕获文本中的长距离依赖关系,这对于理解复杂的语义关系非常重要。
模型结构:
SDN的模型结构包括:
1. 稀疏膨胀卷积层:多层不同膨胀率的卷积层捕获多尺度特征
2. 特征融合模块:整合不同尺度的特征表示
3. 联合解码层:同时进行实体识别和关系抽取
训练阶段:
SDN的训练目标包括实体识别损失和关系抽取损失:
$$\mathcal{L} = \mathcal{L}_{entity} + \mathcal{L}_{relation}$$
其中实体损失$\mathcal{L}_{entity}$是序列标注的交叉熵损失,关系损失$\mathcal{L}_{relation}$是多分类交叉熵损失。
推理阶段:
推理过程通过联合解码层同时输出实体标签和关系标签,然后根据标签组合形成三元组。
算法伪代码:
1 2 3 4 5 6 7 8 9 10 | |
参考¶
- Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
- GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction
- TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
- TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations
- CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning
- CasRel: A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
- 知乎:娄杰:nlp中的实体关系抽取方法总结
- IJCAI 2020_A Relation-Specific Attention Network for Joint Entity and Relation Extraction
- TPLinker 实体关系抽取代码解读
- TDEER:一种高效的联合实体与关系抽取翻译解码框架