在知识图谱构建过程中,实体识别和关系抽取是两个非常基础的任务,前者是一个典型的序列标注任务,目的是将文本中所有的实体抽取出来;后者则需要对所有有关系的实体间的关系进行识别,根据关系是否有层级,可看作是一个(多级)多类分类任务。
今天读了一篇陈丹琦大佬在ACL2021的做实体识别和抽取的文章,标题为“A Frustratingly Easy Approach for Entity and Relation Extraction”,文章的思路没有辜负“frustratingly”这个词,从实验结果上来看,确实是是简单有效。下面我们先简单回顾一下作者的思路,接着聊一聊对实体标注-关系抽取这个典型任务的一些简单的认识。
1. 思路分析¶
作者仍沿用传统的解决方案:先抽实体,再进行关系抽取,考虑到这两个任务一个关注实体,一个关注关系,作者担心共享encoder会对彼此之间存在干扰,因此使用了两个预训练encoder分别做实体识别和关系抽取(这里简记为Entity-encoder,E-encoder和Relation-encoder,R-encoder),实体识别任务目标是抽取出句子中所有的实体,是一个简单的NER任务,这里主要讨论第二部分:关系抽取。
E-encoder负责抽取出所有的实体,假设有$N$个,则两两组和可以生成$\frac{N*(N-1)}{2}$组实体pair,并由于实体对是有顺序关系的,因此每组实体pair中两个实体可以调换一下顺序,这里共可以生成$N(N-1)$对实体pair。每组对应一种实体关系(或无关系),这里没有从原论文中找到确切证据,但个人以为,这种pipeline串接的模型,第二层分类理应加入一个‘Other’标签,以提高整个系统的鲁棒性,减弱由第一层实体识别错误并引入第二层的误差传播。
考虑简单的场景,即关系是无层级的,这种情况下,关系抽取是一个多分类任务,类别数为我们预期构建的知识图谱中的关系总数。这个任务中,输入为两个实体及它们所处的上下文,输出为这一对实体属于所有关系类别的概率分布。在建模过程中,在输入上下文的情况下,我们可以考虑将实体对的embedding引入,也可以将实体对的位置信息引入,总之,需要指示模型,需要进行关系分类的这一对实体是什么。
在这篇文章中,作者在需要做关系抽取的一对实体周围加上了一组特殊标签,这组实体,前者称为subject,后者称为object,分别使用\<S>\</S>、\<O>\</O>包括:
1 2 3 4 | |
在R-encoder中,将标签依次拼接后与原文本拼接,这里各种标签可以作为特殊的token加入词表,同时,开标签的position embedding(以下简作PE)取对应实体的第一个token的PE;闭标签的PE取对应实体的最后一个token的PE,用以指示对应的实体所在的位置信息。
另外,作者认为,一句话中的同一个实体在和不同实体组成Subject-Object pair时,不应该共享相同的embedding,于是,在训练过程中,pair与pair之间引入了独立假设,但是考虑到计算效率,作者也提出了一个用于并行计算的模型框架,即将一句话中的所有实体对的标签全部拼接在原文本后方,同一个entity的标签共享相同的位置embedding(猜测不同标签组之间应该是需要通过mask来进行注意力屏蔽的)。
在上述格式的输入构造完成后,便可输入R-encoder,使用每一个开标签位置对应的输出作为对应实体的表征,接全连接层进行多分类,完成关系的建模。
2. 一点想法¶
这篇文章的创新点在于,引入了一组用于标记的实体标签组,并将这些标签组拼接到输入后方;另外一点是,实体抽取的encoder和实体关系建模的encoder不共享参数。
从整体结构来看,目前大多数图谱构建的工作仍然沿用这种标注+分类二阶段组合的方式来进行,这种模式存在一些缺点:
- 标注模块的误差可能会传递给关系抽取模块
- 关系抽取模块无法影响到标注模块(即标注时无法考虑到其可能与其他实体存在的关系)
- 关系抽取模块的负载太高($N^2$量级)
- 实体-关系组之间引入了独立假设
- 不够优雅
上面都是一些老生常谈,在工业应用中,这种pipeline的方式其实还是主流,因为它解耦了实体的抽取和关系的识别,方便定位业务问题和优化。如果非要对上述“缺点”排个序的话,我认为应该是2>1>3>5>4。
这里也提一个稚嫩的联合抽取的方案:主要思路是,将经典的标注-分类框架变为encoder-decoder架构,我曾使用PointerNet做排序和生成,指针网络可以看做attention机制的简化版本,是否也可以借用它通过解码的方式对实体和关系进行联合抽取呢?
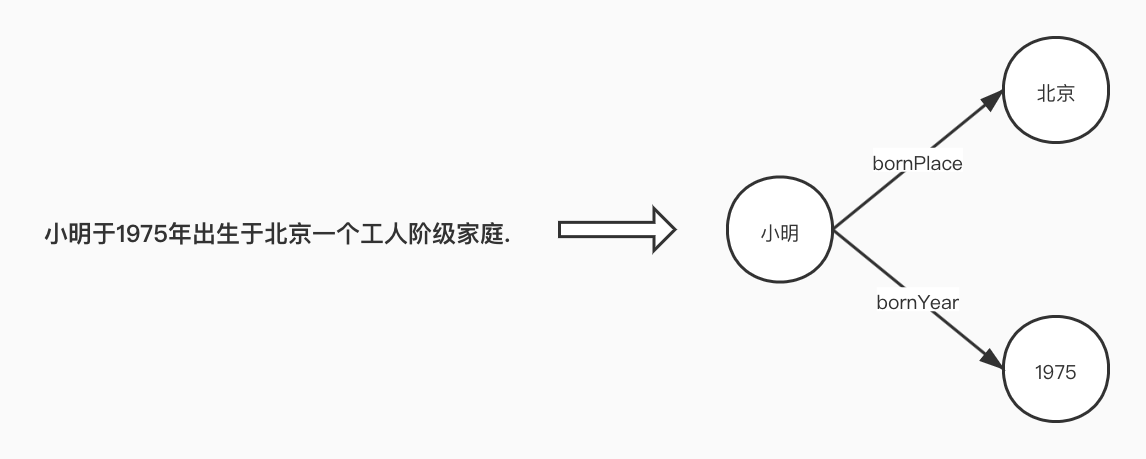
假设共有4种关系,这里命名为$R_0,R_1,R_2,R_3$。
目标给定输入$X$,抽取出其包含的所有的实体$\{E_1,E_2,E_x\}$,同时对存在关系$R_k$的任意一对实体$E_i$和$E_j$,模型需要同时输出实体及关系的三元组$(E_i,E_j,R_k)$。
模型(后文称为新模型):使用encoder-decoder架构,将所有关系拼接原文本输入encoder,decoder使用指针网络,依序解码出所有的三元组。示例如下:
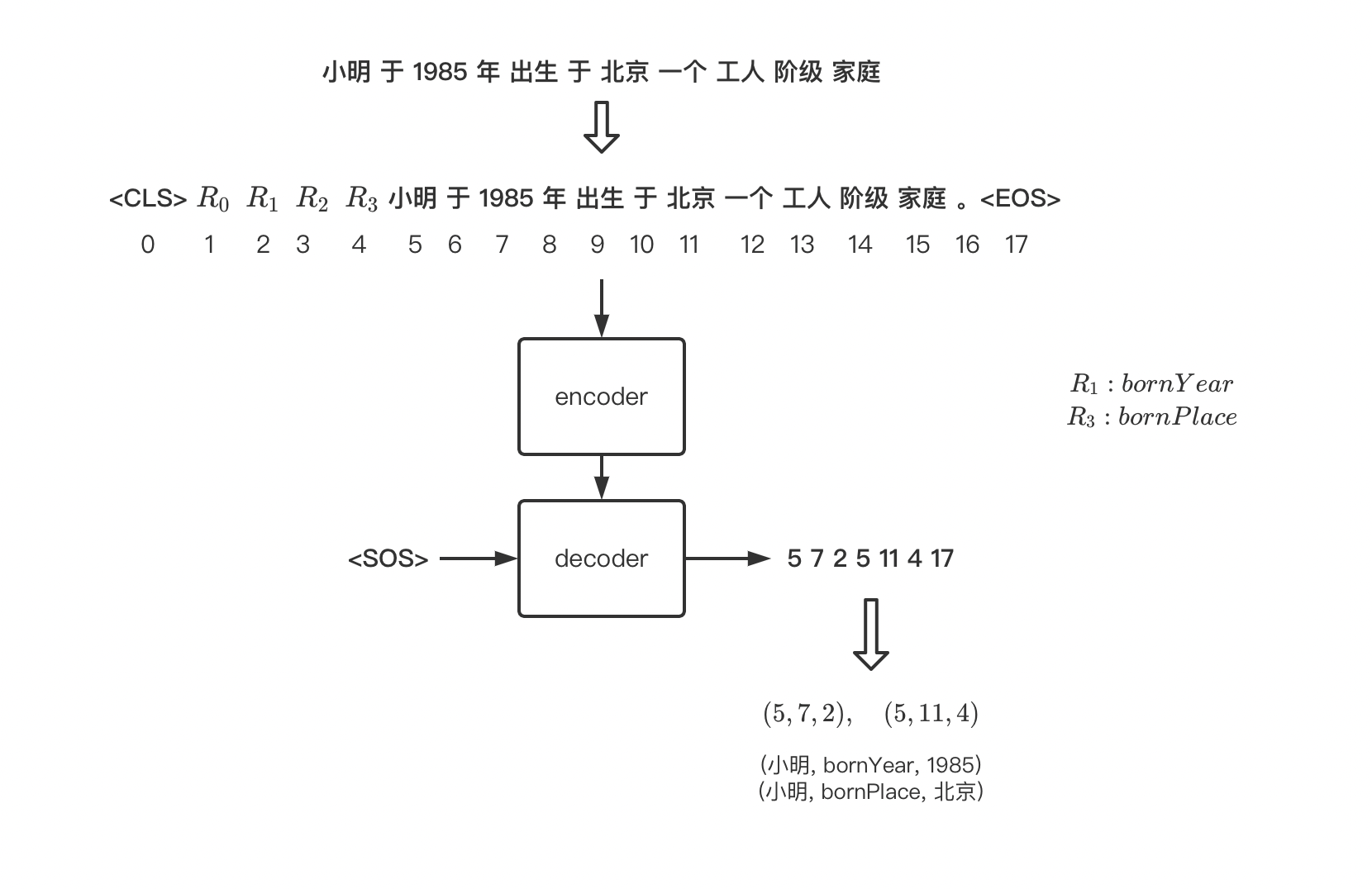
针对上述5个缺点,新模型将实体识别和关系抽取完全融入一个任务中(特别地,将各种关系也视作特殊的“实体”),因此,它天然地解决了问题1、2;再者,指针网络在解码的过程中,每一个时间步,解码器均可以通过attention看到所有的实体、关系之间的概率分布,同时,由于实体可以重复被选择,因此问题3、4也不复存在了,至于最后一点,个人认为,新模型虽然相对pipeline式的模型更为简洁一些,但由于输入的时候,强行将所有关系拼接在输入前方作为解码候选项,仍称不上优雅。
由于只是一个粗略的想法,还没来得及实现,后续计划抽时间找一个公开数据集跑一跑试试。这里先挖个坑,等待实验结果和后续分析⌛️。