本文尝试对GAN在文本领域的应用现状作一个粗略的调研。
首先介绍GANs的原理和其在图像生成上的应用,接着讨论直接将GANs推广到文本生成时会遇到的一些问题。针对这些问题,介绍几种将GANs应用于文本的实现方案,如微调GANs结构、将强化学习中的PG(policy gradient)引入GANs,以及一些“类GANs模型”的尝试。接着,从当前领域中热门的研究中选取若干典型的工作,并进行简单地解读,然后,针对条件生成,介绍几篇有关CGAN和类CGAN的研究,最后,对易混淆的强化学习(RL)、生成对抗网络(GANs)、变分自编码器(VAE),给出简单的概念澄清。
一、GANs:由图像到文本¶
1.1 GANs原理¶
Generative Adversarial Networks (GANs)
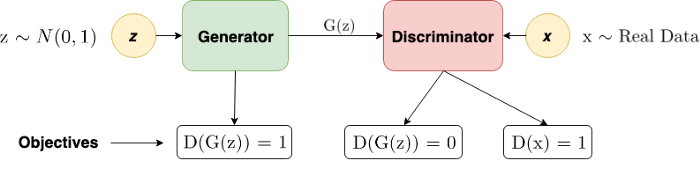
GANs本质上是一个minimax游戏,其目标函数为:
$$\min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))]$$
1.2 GANs for Image¶
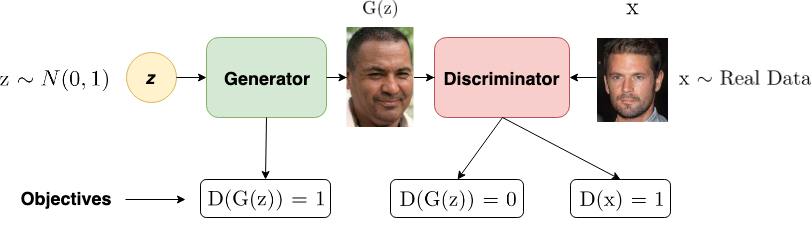
GAN用于图片生成时,隐变量$z$从分布中采样得到,$x$从真实数据中采样得到,
对于生成器(Generator):通过$z$生成分布$G(z)$,目标:$\arg\max P( D(G(z)))$;
对于判别器(Discriminator):输入生成器的输出$G(z)$和真实采样$x$,目标:$\arg\max P(D(x))-P(D(G(z)))$
无论是真实的图片还是真实的图片,都是一个实值张量,因此生成器和判别器之间,梯度都是可以正常传递的。
1.3 将GANs思想推广到文本¶
当我们把GAN的思想推广到文本生成时会发生什么?
Seq2seq是目前应用比较广泛的文本生成框架,以RNN decoder为例,在时间步$t$,RNN通过以下计算获得当前时间步最有可能的词$token^\star$:
$$h^t=RNN(h^{t-1}, w^{t-1})$$
$$Idx_{token^\star}=onehot(Softmax(fc(h^t)))$$
然后通过最小化交叉熵损失来调整RNN的参数。
下面我们将基于RNN的decoder与GAN中的Generator关联起来,并尝试分析为什么传统的GAN思想无法直接推广在文本生成领域。
在GAN中,则不是使用交叉熵来调整生成器的参数,而是通过$\arg\max P( D(G(z)))$来实现,这里就会存在一个问题,$G(z)$是通过$\arg\max$操作获得的(这个过程也称为sampling),$\arg\max$操作是一个不可导的过程,会导致梯度断开,导致生成器和判别器之间无法进行正常的梯度传递,训练无法正常进行。针对这个问题,很自然的一个想法,我们是否可以不通过argmax来获取onehot表示,直接将生成器的softmax分布传递给判别器?这种方式也是不可行的,原因是,在这种情况下,判别器遇到的负样本一般情况下都是一个浮点张量,而从真实数据中采样的样本$x$一般是onehot张量,这种正负样本的分布差异,自然会导致判别器“偷懒”,比如,判别器是否可以仅仅通过“数”输入中1的个数来判断是否是真实样本?这样的话,判别器就失效了。
另外也可以从loss的角度来分析:一般情况下GAN使用$JS$散度来衡量真实分布和生成分布的差异(有关GAN使用的几种度量的介绍见下文3.1.1),注意到只有在两个分布有交叠时,才能使用$JS$散度来衡量其距离(否则的话,$JSD$为$\log2$),但很明显,如果生成器的结果不经过softmax,其生成出multinoulli distribution$^{13}$分布的概率应该是接近0的,这种情况下,自然也不能对生成器进行有效的权重更新。
另外一个角度看,使用与真实label的交叉熵也好,使用判别器的判别结果也好,都是对当前模型参数做的微调,想象某一个时间步$t$时softmax的结果为$[0.03, 0.26, 0.18, 0.05, 0.27, 0.16]$,通过softmax采样得到的token index为4,这里可能存在的一个问题是,对同一个样本的多次微调不一定能够改变softmax结果的最大值的index,也即不一定影响sampling的结果,那么对判别器来讲,其训练过程也会失去方向。
二、GANs在文本生成上的应用场景和优势¶
目前,文本GAN已经能够生成流畅的文本,大部分无约束GAN相关论文采用的评测数据集包含以下几个:
autoencoder-based methods may fail when generating realistic sentences from arbitrary latent representations.
目前无论是修改原生GAN结构或者采用PG思路的文本GAN,其应用基本限制在无约束文本生成上,在一些需要控制生成方向的任务,如机器翻译、对话生成、文本摘要等,则需要采用Conditional GAN,这里称前者为无约束的GAN,后者称为Conditional GAN,目前,Conditional GAN在可控文本生成领域的应用效果与Seq2seq架构相比仍有一定差距。
三、GANs如何应用于文本?¶
目前针对GAN在文本生成领域的应用,主要有以下几种GAN改进思路:
- 微调GAN的结构
- 使用Wasserstein-divergence进行距离衡量
- 通过Gumbel-Softmax估计(对softmax的一种连续化的估计)
- 通过强化算法和策略梯度(Policy Gradient)(基于强化学习的)
- 生成器结果在连续空间中传递给判别器(避免在离散空间交互)
以下分别介绍上述三种方案。
3.1 微调GAN结构¶
目前主要有两种主流方案,其一主要针对分布的距离衡量做工作,另一个则针对sampling无法进行梯度传递进行改进。
3.1.1 使用Wasserstein-divergence¶
Wasserstein-GAN,又称WGAN,其在生成对抗领域甚至与原版的GAN平分秋色。
在介绍Wasserstein-divergence在GAN中的应用之前,首先了解一下有关距离衡量的内容。
散度
散度(Divergence)或称发散度,是向量分析中的一个向量算子,将向量空间上的一个向量场(矢量场)对应到一个标量场上。散度描述的是向量场里一个点是汇聚点还是发源点,形象地说,就是这包含这一点的一个微小体元中的向量是“向外”居多还是“向内”居多。散度是向量场的一种强度性质,就如同密度、浓度、温度一样,它对应的广延性质是一个封闭区域表面的通量,所以说散度是通量的体密度$^{7}$。
KL散度(Kullback-Leibler divergence,简称KLD)
KL散度来源于信息论。KL散度又称为相对熵。在信息论中,分布$p$的熵定义为:
$$H=-\sum_\limits{i=1}^Np(x_i)\log p(x_i)$$
对熵稍加改动,即可得到相对熵:
$$D_{KL}(p\Vert q)=-\sum_\limits{i=1}^Np(x_i)\cdot (\log p(x_i)-\log(q(x_i))$$
KL散度是两个概率分布$p$和$q$差别的非对称性的度量。 KL散度是用来度量使用基于$q$的分布来编码服从$p$的分布的样本所需的额外的平均比特数($\log$以$2$为底时)。典型情况下,$p$表示数据的真实分布,$q$表示数据的理论分布、估计的模型分布、或$p$的近似分布$^6$。
在生成对抗网络中,多使用KLD对两个分布的距离进行度量。
JS散度(Jensen-Shannon divergence)
JS散度也用于度量两个概率分布的相似度,它是KL散度的变体,解决了KL散度的非对称问题。JSD的取值在$0 \sim 1$之间,其定义如下:
$$JS(p_1\Vert p2)=\frac{1}{2}KL(p_1 \Vert \frac{p_1+p_2}{2}) + \frac{1}{2}KL(p_2 \Vert \frac{p_1+p_2}{2})$$
Wasserstein散度(Wasserstein-divergence)
文章$^5$使用芬切尔共轭(Fenchel Conjugate)的性质证明了,任何$f-divergence$都可以作为KLD(或JSD)的替代方案,$f-divergence$的定义如下:
$$D_f(p \Vert q) = \int_xq(x)f(\frac{p(x)}{q(x)})dx$$
其中,$f(\cdot)$称为$f$函数,它必须满足两个条件:
- $f$是凸函数(convex function)
- $f(1)=0$
可以看出,KL-divergence是f-divergence的一种。而Wasserstein-divergence也是对KL-divergence的一种改进。中文译为“推土机距离”,可以形象地理解为,将两个分布看作两个土堆,Wasserstein-divergence就是计算将两个土堆堆成一样的形状所需要的泥土搬运总距离。
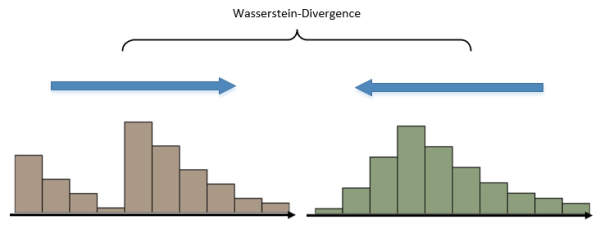
相比原版的GAN,Wasserstein-divergence更能体现出分布循序渐进的过程,在GAN的训练过程中,无论是KL散度还是JS散度,在开始训练后的很长一段时间内,散度值都为$\log2$,而Wasserstein-divergence的值则是平滑变化的。
由于Wasserstein-divergence克服了JS散度的“两个分布必须包含重叠部分”的缺点,我们也就自然地可以计算生成器的softmax分布和真实onehot分布的距离了。
值得注意的是,Wasserstein-divergence提出并不针对GAN在文本生成上面临的问题,事实上,其对于GAN理论本身的意义更为重要。文章$^8$使用GAN在文本生成上做了实验,结果表明,加入Wasserstein-divergence的GAN至少处于可以训练的状态了(虽然生成效果距离MLE结果还有一段距离)。

3.1.2 使用Gumbel-softmax替换softmax¶
上面已经提到了由$\arg\max$带来的困境:采样后梯度无法传播;不采样,softmax分布和onehot分布不重叠,无法计算距离;1.1部分讨论了不采样、换度量的方法,接下来讨论如何能在采样的情况下保持梯度。
这篇文章$^9$给出的答案是Gumbel-softmax,它最早提出用于类别的重参数化,应用到GAN的改进目标可以认为是设计一个更“强大”的softmax,使得能够代替原生GAN中的softmax+argmax操作,直接进入分布的距离计算。
原生GAN的生成器输出为$y_{old}=onehot(\arg\max(softmax(h)))$,Gumbel-softmax通过$y_{new}=softmax(\frac{1}{\tau}(h+g))$直接给出近似sampling的输出。参数中,$\tau$称为逆温函数,当$\tau \rightarrow 0$时,上式等同于$onehot(\arg\max(\cdot))$;当$\tau \rightarrow \infty$时,输出接近均匀分布,可以给$\tau$一个较大的初始值,在训练中逐渐向0逼近。
文章$^9$使用融合了Gumbel-softmax的GAN进行了长度为12的CFG(上下文无关文法)文本生成,结果可参考下图。

可以看出,在少数样例上也得到了比较满意的结果,但总体来看,效果仍不理想。
3.2 引入强化学习思想¶
现在我们暂时先把神经网络的概念放在一边,考虑如何从强化学习的角度考虑文本生成,下面以文本生成为例,讨论强化学习的一些基础概念。
3.2.0 强化学习部分术语整理¶
reward: 环境提供给agent的一个可量化的标量反馈信号,用于评价agent在某个时间步的action的好坏;
agent: 中文一般翻译为智能体,是强化学习的核心,其可以感知环境的状态(state),并根据环境提供的强化信号(reward signal),通过学习,选择一个合适的动作(Action),最大化长期的reward值;
episode: An episode is one complete play of the agent interacting with the environment in the general RL setting. Episodic tasks in RL means that the game of trying to solve the task ends at a terminal stage or after some amount of time. 一般表示agent从开始执行任务到一次任务执行完毕,或达到某一个阶段性的时间点,如一个游戏回合中,智能体被击毙或击毙对方boss;
3.2.1 Policy¶
我们定义强化学习中的决策执行者为agent,可以定义agent的:
状态$s$(state):截止目前为止生成的文本
动作$a$(action):下一步应该生成哪一个词(即,词表的大小即是选择空间)
当agent最终生成了结尾符$
因此,我们可以把判别器看作对agent的一个reward函数。接下来需要讨论的是,agent在特定的状态$s$如何选择合适的动作$a$呢?这里要引出policy的概念:
Policy是一个函数$\pi(a\mid s,\theta)$,该函数受参数$\theta$控制,基于当前状态$s$,输出所有动作$a$的概率分布,agent通过这个概率分布来进行action采样(而不是直接采用概率最高的,这一定程度上也给了agent一定的探索性)。
至此,我们把agent做文本生成的任务归结到policy函数$\pi^\star$的选择上,即确定最优参数$\theta^\star$来最大化某一个评价指标$J(\theta)$。
策略梯度法(Policy gradient)是用于寻找最优policy函数$\theta^\star$的一类策略优化方法,它基于评价指标$J(\theta)$对$\theta$的梯度。即为了寻找最优的参数$\theta^\star$,可以对$J$执行梯度上升算法:
$$\theta_{t+1}=\theta_t+ \alpha \widehat{\nabla J\left(\boldsymbol{\theta}_{t}\right)}$$
其中,$\widehat{\nabla J\left(\boldsymbol{\theta}_{t}\right)}$表示梯度的估计,这里的估计由策略梯度定理(Policy gradient theorem)保证:
$$\nabla J(\boldsymbol{\theta}) \propto \sum_\limits{s} \mu(s) \sum_\limits{a} q_{\pi}(s, a) \nabla \pi(a \mid s, \boldsymbol{\theta})$$
其中,$\mu(s)$表示agent进入状态$s$的可能性(归一化的);$q(s,a)$表示从状态$s$中选择动作$a$的质量(quality)。
评价指标$J(\theta)$的梯度估计是所有状态、所有动作上的累加。但是在实际应用中,我们希望能够仅通过当前的状态$S_t$和动作$A_t$来计算梯度的估计,接下来引入强化算法(Reinforce algorithm)来解决这一问题。
3.2.2 Reinforce Algorithm¶
回顾梯度的估计:
$$\nabla J(\boldsymbol{\theta}) \propto \sum_\limits{s} \mu(s) \sum_\limits{a} q_{\pi}(s, a) \nabla \pi(a \mid s, \boldsymbol{\theta})$$
$\mu_s$其实可以看做policy$\pi$下的状态$s$出现的概率,所以外层的累加可以看做内层关于$\pi$的期望:
$$\mathbb{E}_{\pi}\left[\sum_{a} q_{\pi}\left(S_{t}, a\right) \nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)\right]$$
现在考虑内层的累加,内层引入$\pi(a\mid S_t,\boldsymbol{\theta})$,表示基于状态$S_t$的动作概率分布:
$$\mathbb{E}_{\pi}\left[\sum_{a} \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right) q_{\pi}\left(S_{t}, a\right) \frac{\nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)}\right]$$
$\sum_\limits{a} \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right) q_{\pi}\left(S_{t}, a\right) $是在所有动作$a$上的累加,可以变形为:
$$\sum_{a} \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right) q_{\pi}\left(S_{t}, a\right) =q_\pi(S_t,A_t)$$
则有:
$$\nabla J(\boldsymbol{\theta}) \propto \mathbb{E}_{\pi}\left[q_{\pi}\left(S_{t}, A_{t}\right) \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta_t}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta_t}\right)}\right] $$
至此,我们可以仅通过一个样本$(S_t,A_t)$来进行梯度估计了!
将$q_\pi(S_t,A_t)$记为$G_t$,可以得到强化算法的更新策略:
$$\boldsymbol{\theta}_{t+1} \doteq \boldsymbol{\theta}_{t} + \alpha G_t \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}$$
$G_t$可以认为是从当前时间$t$到当前回合(episode)结束的累加reward的期望;$\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)$为一个向量,它指示当我们在次进入状态$S_t$时,采取动作$A_t$的概率增加最大的方向。
3.2.3 RL引入text GANs¶
接下来我们将上文的一些结论引入GANs中。
首先构建一个判别器,它的输入是一段文本,输出为一个值,表示这段文本是真实文本(非机器生成文本)的概率。可以使用任何一个文本分类模型(如RNNs、CNNs等),其输出作为对输入的reward,将在本回合结束时传回生成器用于policy参数$\theta$的更新。
接着构造一个生成器,该生成器中需要包含我们在上文中提到的policy函数$\pi(a\mid s,\boldsymbol{\theta})$,$\boldsymbol{\theta}$对应生成器的参数,其将会按照上文中得到的reinforce algorithm进行更新。生成器能够接收一段文本,输出下一个token的概率分布(使用RNN就可以):
$$h_t=RNN(h_{t-1},x_t)$$
$$p(a_t \mid x_1,x_2,...,x_t)=softmax(b+Wh_t)$$
由于我们使用中间反馈(intermediate rewards)$R_k$来计算$G_t$,但判别器的reward仅在每个回合结束时才会向生成器传递,这就意味着,只有生成器生成一个完整的句子后才能得到判别器的反馈,SeqGAN$^{10}$通过引入Monte-Carlo rollouts来解决这个问题:
$$R_{t}=\frac{1}{N} \sum_\limits{n=1}^{N} D_{\phi}\left(Y_{1: T}^{n}\right), Y_{1: T}^{n} \in MonteCarlo \left(Y_{1: t} ; N\right)$$
具体细节将在本文第四节介绍。
3.2.4 基于RL的GANs可能存在的问题¶
- 采样方差
由于中间策略梯度是由采样获得的,回合与回合之间的方差会很大,导致训练过程十分不稳定,收敛较慢,针对这个问题,大部分GAN模型$^{10,16,18,20,21,23}$都会选择在对抗训练之前,对生成器和/或判别器使用MLE进行预训练。
- 局部最优点
策略梯度方法容易收敛到局部最优解,尤其当状态-动作空间很大时。(比如文本生成时,每个时间步的选择空间为词表大小,接近十万量级)。
3.3 其他架构¶
文章$^{11}$将auto-encoder引入GAN,这里我们简单地介绍auto-encoder是如何引入的,它解决了什么问题。该文章具体内容将在本文第四节中介绍。
首先简单介绍一下auto-encoder架构,auto-encoder包含两部分:encoder和decoder。encoder负责将输入$x$投影到维度相对更小的空间中,生成一个潜向量,decoder负责从潜向量中重建输入$x$,得到$x'$。auto-encoder的作用是捕捉输入中更通用的、更本质(essential)的特征,并尽量忽略输入中的噪声。
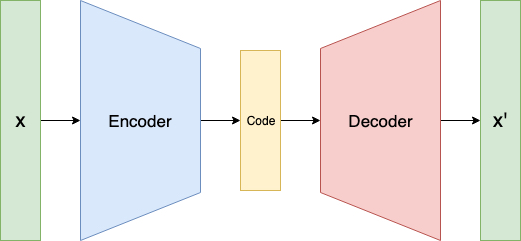
那么auto-encoder如何能够引入GAN呢?
回顾我们在1.3中讨论的将GAN由图像领域引入文本领域时面临的本质问题:离散的生成器采样结果。
现在稍微改变一下GAN在文本生成上的思路:将句子的生成任务看作在句子空间中的句向量采样问题(而不是前述的序列的每一个token的采样问题)。也即是说,生成器的输出是一个潜空间的句向量(而不是一个句子)。
那么判别器的任务也发生了改变:判断生成器产生的句向量是不是“真实的”。那么,下一个问题就是,“真实的”句向量从哪里来?这里就可以引入auto-encoder了,首先,在训练GAN之前,可以先在大量语料上训练一个auto-encoder,训练完成后,从真实语料中采样得到的句子经过aoto-encoder编码得到的句向量,作为“真实的”句向量;而生成器生成的句向量则作为负样本,即“虚假的”句向量。
当GAN训练到最优时,我们可以取GAN的生成器生成的句向量(训练收敛后,对于判别器来说,该向量已经是“真假难辨”),然后将此向量输入auto-encoder的decoder,得到$x'$作为生成的结果。
四、无约束文本GAN调研¶
4.1 近年工作总览¶
| 时间 | paper | Source |
|---|---|---|
| 2016 | GANs for Sequences of Discrete Elements with the Gumbel-softmax Distribution | arXiv |
| 2016 | Generating Text via Adversarial Training | NIPS |
| 2017 | Adversarial Feature Matching for Text Generation | ICML |
| 2017 | Adversarial Learning for Neural Dialogue Generation | ACL |
| 2017 | SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient | AAAI |
| 2017 | RankGAN: Adversarial Ranking for Language Generation | NIPS |
| 2018 | MASKGAN: Better Text Generation via Filling in the _____ | ICLR |
| 2018 | LeakGAN: Long Text Generation via Adversarial Training with Leaked Information | AAAI |
| 2018 | STWGAN-GP: Generating Text through Adversarial Training using Skip-Thought Vectors | NAACL |
| 2019 | RelGAN: Relational Generative Adversarial Networks for Text Generation | ICLR |
| 2019 | PPOGAN: Training Language GANs from Scratch | NIPS |
| 2020 | Improving GAN Training with Probability Ratio Clipping and Sample Reweighting | NIPS |
| 2021 | Refining Deep Generative Models via Discriminator Gradient Flow | ICLR |
4.2 文章内容摘要¶
这部分会重点关注4.1表格中提到的文本生成榜单上的几篇经典的论文 ,榜单参考paperwithcode的text generation子项目$^{12}$。
4.2.1 GANs for Sequences of Discrete Elements with the Gumbel-softmax Distribution$^{14}$¶
在3.1.2中已经介绍了Gumbel-softmax的作用,这篇文章使用其替换原有的onehot(argmax(softmax)),并将其应用在上下文无关文法的文本生成上,在训练完成后,通过生成器可以通过在随机噪声中采样,来生成一段文本。
网络结构方面,generator使用LSTM预测下一个词汇的概率分布,使用其提出的Gumbel-softmax对概率进行近似归一化,descriminator使用LSTM,对生成器生成的序列进行鉴别(注意,在生成器生成完成一个token序列后,才会被输入判别器)。
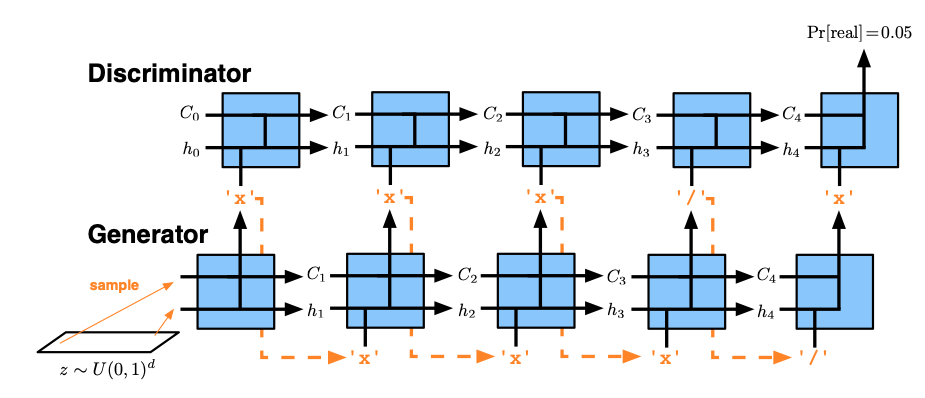
4.2.2 Generating Text via Adversarial Training$^{15}$¶
模型结构上,判别器使用CNN;生成器使用LSTM,在解决argmax不可导这个问题上,使用了一个soft-argmax:
$$y_{t−1} = W_e softmax(Vh_{t−1} \odot L)$$
其中$W_e$是embedding table。
预训练策略:对生成器,使用标准的auto-encoder架构预训练、对于判别器,使用confusing training策略,具体是,对每一条训练数据,随机调换其中的两个词,作为负样本,训练判别器识别出这些被调换位置的句子。
训练策略:由于LSTM的训练比CNN要困难一些,因此生成器每更新五次参数,判别器更新一次。
实验中也观察到了,即便在训练了很长一段时间之后,判别器仍然具有非常强的判别能力,生成器“骗过”判别器的概率只有$8\%$。
作者也随机选择了两个样本点,并使用连接这两点的路径上采样得到的点通过生成器进行文本生成,用于验证其生成结果的平滑性,结果如下图所示:

这篇也相当于是在标准的GAN的基础上,对argmax做了优化,同时使用JS散度(对称化的KL散度)来进行真实文本/人工文本特征向量之间的距离计算。
4.2.3 SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient$^{23}$¶
传统GAN应用于文本生成时面临两个主要问题:
- 采样导致梯度无法传递
- 判别器仅能对完整的生成序列进行鉴别,无法在文本生成中干涉生成的方向/效果
SeqGAN针对上述问题:
- 使用策略梯度法更新参数,解决上述问题1
- 在每一个state-action步,使用蒙特卡洛搜索向生成器传递reward
模型选择:生成器:LSTM;判别器:CNN(+highway)。
考虑到生成过程中应当考虑全局的收益,生成器是需要在某一个时间步$t$上,对当前的action有所取舍的,作者提出基于Monte-Carlo搜索的方式,对$t+1...T$上的token进行采样,并对多个采样结果的判别器分数进行平均,得到当前时间步上对生成器的reward,用于解决上文中提到的第二个问题。
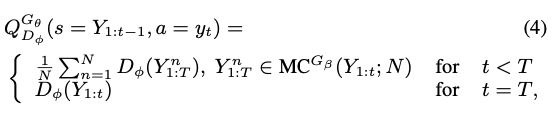
在GAN训练之初,作者首先在数据集$\mathcal{S}$上使用MLE对生成器$G_\theta$进行预训练;接着,使用$G_\theta$生成一些负样本,结合数据集$\mathcal{S}$上采样得到的正样本,对判别器$G_\phi$进行预训练。全部预训练完成后,生成器和判别起交替训练,直至SeqGAN收敛。
贴一下伪代码,方便理解训练流程:

用于效果验证的任务:
- 古诗生成
- 演讲生成
- 音乐生成
4.2.4 RankGAN: Adversarial Ranking for Language Generation$^{16}$¶
经典的GAN的判别器是一个二分类器,RankGAN作者指出,二分类的判别器对于多样的自然语言来说,似乎有些不足,因此作者将判别器由一个二分类器改为一个排序模型(learning-to-rank),在提升判别器能力的同时,对生成器的能力提升也起到了促进作用。
模型结构:generator and a ranker
SeqGAN is the most relevant study to our proposed method. The major difference between SeqGAN and our proposed model is that we replace the regression based discriminator with a novel ranker, and we formulate a new learning objective function in the adversarial learning framework.
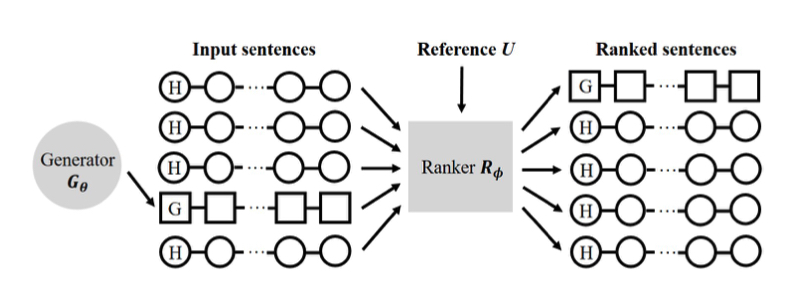
Objective:
$$\min _{\theta} \max _{\phi} \mathfrak{L}\left(G_{\theta}, R_{\phi}\right)=\underset{s \sim \mathcal{P}_{h}}{\mathbb{E}}\left[\log R_{\phi}\left(s \mid U, \mathcal{C}^{-}\right)\right]+\underset{s \sim G_{\theta}}{\mathbb{E}}\left[\log \left(1-R_{\phi}\left(s \mid U, \mathcal{C}^{+}\right)\right)\right]$$
$G_\theta$:生成器;
$R_\phi$:ranker;
$\theta,\phi$:生成器和ranker的参数;
$s \sim \mathcal{P}_h$:$s$来自真实样本
$s\sim G_\theta$:$s$来自生成器
$U$:we randomly sample a set of references from human-written sentences to construct the reference set $U$
$\mathcal{C}^+,\mathcal{C}^-$:the comparison set with regard to different input sentences $s$,当$s$来自真实采样时,$\mathcal{C}^-$从生成样本中采样;当$s$是生成文本时,$\mathcal{C}^+$从真实样本中采样;
下面推导一下$\log R_{\phi}\left(s \mid U, \mathcal{C}\right)$的公式:
对于Ranker来说,其接收的是一个文本,这个文本可能来自真实样本,也可能是生成器生成的假样本,Ranker的目标是,使真样本的排名尽可能高,假样本的排名尽可能低:
针对任意一个样本$s$,我们都会为其采样一个排序参照集$\mathcal{C}$:
当文本来自真实样本时($s \sim \mathcal{P}_h$),我们从机器生成的文本中进行采样,得到$\mathcal{C}^-$;
当文本来自机器生成时($s\sim G_\theta$),从真实样本中采样,得到$\mathcal{C}^+$;
则,待排序的样本集合为$\mathcal{C'}=\mathcal{C} \bigcup \{s\}$。
我们通过余弦相似度来计算两个文本向量的相关度(relevance score)$\alpha$:
$$\alpha(s \mid u)=\operatorname{cosine}\left(y_{s}, y_{u}\right)=\frac{y_{s} \cdot y_{u}}{\left\|y_{s}\right\|\left\|y_{u}\right\|}$$
对参照集中的每一个参照样本$u$,依照下式计算rank score:
$$P(s \mid u, \mathcal{C})=\frac{\exp (\gamma \alpha(s \mid u))}{\sum_{s^{\prime} \in \mathcal{C}^{\prime}} \exp \left(\gamma \alpha\left(s^{\prime} \mid u\right)\right)}$$
则,对于输入的文本$s$,可以计算其期望的排序分数(对数化)为:
$$\log R_{\phi}(s \mid U, \mathcal{C})=\underset{u \in U}{\mathbb{E}} \log [P(s \mid u, \mathcal{C})]$$
该分数可以用于计算$G_\theta$和$R_\phi$的目标函数。
训练过程中,为了解决只能在句子生成完成后才能将reward传递给生成器$G_\theta$的问题,本论文也使用了Monte Carlo rollout方法来模拟计算生成过程中的reward,具体的,在时间步$t$,生成器已经生成的序列为$s_{1:t-1}$,根据已生成序列,使用$G_\theta$对后续的序列进行连续采样,直至达到设定最大长度或生成结束符,我们可以把生成的序列$s_{t:}$看作生成器在当前时间步的“期望路径(path)”,执行上述过程$n$次,可以得到$n$个期望路径,每个路径都可以于原有已生成的序列$s_{1:t-1}$构成一个完整的句子(只要句子完整,我们就可以使用判别器来计算它的排序分数了(排序分数是对这个句子的质量的一个衡量)),至此可以得到$n$个分数,平均一下,就可以作为当前时间步$t$的期望reward了。
讨论:本文提出的RankGAN,当生成器能够模拟真实的输入分布$P_h$,判别器无法对真实句子和生成句子作正确排序时,认为达到了纳什均衡(Nash Equilibrium),但正如文献$^{17}$中讨论的,对于一个non-Bernoulli GAN,目前仍无法确定如何才能达到这个均衡。
评估方式:BLEU、人工评估
数据集:
- 中文诗词:使用13123首五言诗作为训练数据
- COCO:COCO是一个image caption数据集,其中的caption是人编写的(本文仅仅使用了caption而没有使用图片),本文使用8w条用于训练,5k条用于验证
- 莎士比亚戏剧
4.2.5 LeakGAN: Long Text Generation via Adversarial Training with Leaked Information$^{21}$¶
正如标题所说,这篇文章关注长文本的生成:
We allow the discriminative net to leak its own high-level extracted features to the generative net to further help the guidance.
关键词是leak,即在训练时,判别器向生成器传回的不仅仅是判别结果,还有更高层的一些feature(high-level extracted features),而生成器则通过一个Manager模块,负责将这些信息整合到当前的生成流程中。
模型结构如下:
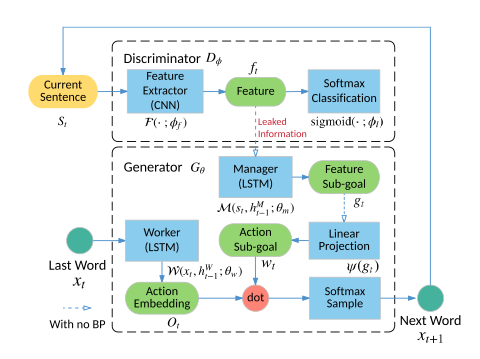
可以看到,较传统的GAN,判别器接受截至目前生成的句子,其改动是,保留判别器中的高层次的(接近输出层的)feature,作为“泄漏”的信息传递给生成器;
对于生成器而言,也由传统的一个RNN扩展为两个RNN,分别称为Manager和Worker,Manager负责接收判别器传过来的泄漏的信息,进行一系列处理;Worker接收上一个词的embedding,输出action embedding,然后与Manager处理后的信息进行点积得到最终的分布,经过softmax即可生成下一个词。
数据集:
We use EMNLP2017 WMT News, COCO Image Caption and Chinese Poems as the long, mid-length and short text corpus, respectively.
训练时的trick:
1. bootstrapped rescaled activation
在训练初期,判别器的能力强于生成器,导致其回传给生成器的reward非常低,训练会趋于vanishing状态,本文也借鉴RankGAN的思想,引入了一个基于排序的bootstrapped rescaled activation,其本质是为了对reward做一个退火(升温),在训练过程中,对reward的缩放因子进行动态调整。两个好处:
- 保持每个mini-batch的方差和均值,保持数值稳定性
- 缓解梯度消失问题
2. 交叉训练(Interleaved Training)
模式崩溃(mode collapse)是传统GAN训练中面临的一个比较严重的问题,这里引入交叉训练的思想,不同于上述其他方案,本文采取监督训练(MLE)和对抗训练交叉进行的形式(前述几篇文章的思路一般是,先对生成器、判别器做预训练,训练完成后,进行对抗训练),比如,每15轮对抗训练后,会进行一次预训练。
4.2.6 RelGAN: Relational Generative Adversarial Networks for Text Generation$^{18}$¶
目前提出的多数GAN模型,都使用LSTM作生成器,本文分析其可能具有以下问题:
- 对抗训练中,判别器loss很快降到最低值,意味着判别器比生成器具有更强的能力(生成器太弱);
- 模式崩塌可能部分是由生成器容量低(incapicity)导致的;
- 由于LSTM只能将截至当前已生成的信息压缩到一个hidden state中,所以对于长文本生成场景,优势不明显;
因此,这篇针对这个问题,本文引入了一个"强大的"模块:“relational memory”,即通过设置多个记忆槽(a set of memory slots),多个槽之间通过self attention来进行交互。另一篇文章$^{19}$的实验结论表明,在语言模型方面,relational memory优于LSTM。
本文对判别器结构也进行了改进,传统的基于CNN的判别器,将序列的embedding矩阵通过$W$进行变换后输入CNN进行分类,本文仍然沿用这个方式,但是使用了多个$W_{e}$对embedding矩阵进行特征抽取,然后经过一个共享参数的CNN层,得到多个结果后取平均,作者认为使用这种方式,每个特征矩阵都能够关注某一个特定的模式,供CNN分类模块进行参考(类似Multi-head Attention中的Multi-head或卷积网络中的Multi-channel)。
值得注意的是,这篇文章使用了和4.2.1中相同的Gumbel-softmax来对采样过程进行近似,使得该过程的梯度能够保持。
RelGAN is the first architecture that makes GANs with Gumbel-Softmax relaxation succeed in generating realistic text.
训练技巧:
- 采用RSGAN中的loss
- 仅对生成器进行预训练(不同于TextGAN、LeakGAN、MaskGAN需要同时对生成器和判别器进行预训练。)
作者在COCO数据集上进行了消融实验,实验结果表明,相比LSTM,relational memory带来的提升明显,同时,相对于使用强化学习的方式训练,使用Gumbel-softmax带来的BLEU-2的提升非常明显。
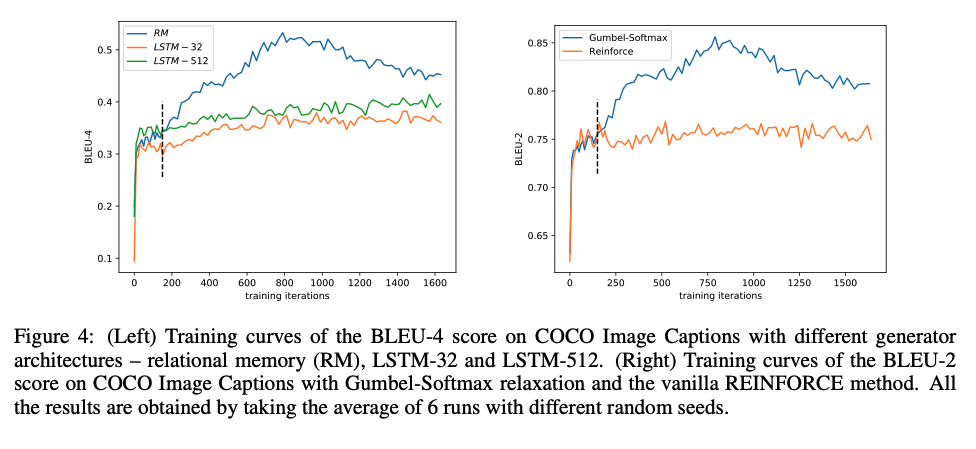
不过,有一点需要注意,在对比Gumbel-softmax时,作者强调是和“vanilla REINFORCE”作的对比,(猜测)这里原生的强化算法应该指的是,当序列生成完成后,判别器才会进行判别,然后将reward传给生成器(区别于使用蒙特卡洛搜索的,在每个时间步进行reward回传的模型)
同时,作者针对判别器的“多channel”也进行了一些实验对比:
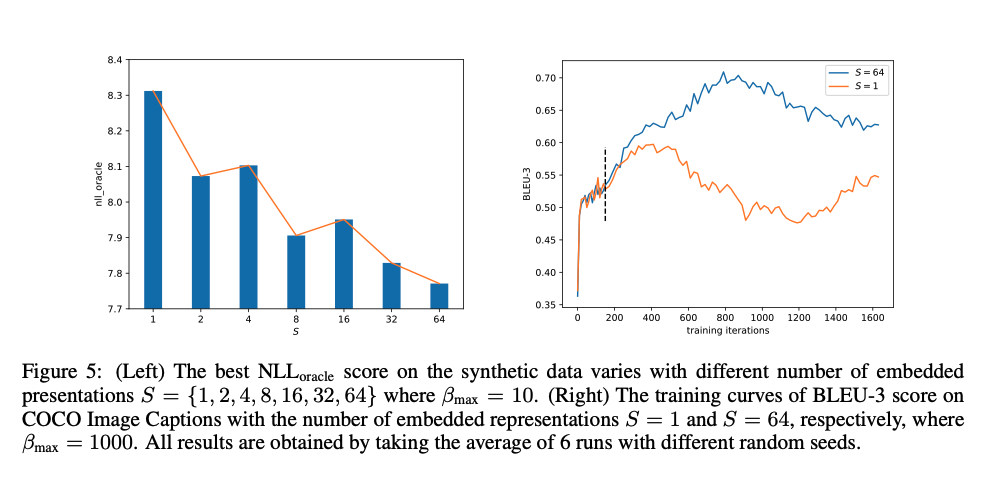
实验表明,判别器采用类似多通道的形式进行特征提取,的确能够对效果带来比较大的提升(10%的BLEU-3提升)。
回顾3.1.2、4.2.1中讨论的,2017年最开始有研究者将Gumbel-softmax应用到文本GAN但生成表现比较一般,到本篇论文发表的近3年左右的时间,文本GAN的方向一度向强化学习靠近,但这篇文章从生成器表达能力太弱的角度出发,引入relational memory网络替代LSTM,同时对判别器进行多通道的特征提取,通过比较详尽的消融实验证明,文本GAN也可以基于传统GAN框架,RL不是必须的。个人认为,使用Gumbel-softmax近似采样这个思路的GAN结构相对基于RL的模型更加优美,这篇文章也从效果上证明:不仅美,而且强!
4.2.7 Adversarial Learning for Neural Dialogue Generation$^{20}$¶
-
使用判别器来区分句子是真实的还是机器生成的,并将输出概率作为奖励传递给生成器,期望生成器生成更加符合真实数据的句子。
-
生成器(Seq2Seq)在目标端使用 softmax 函数完成词语的生成——解决了Seq2Seq使用极大似然估计作为目标函数导致生成重复、无意义等问题。
-
判别器(层次化编码器)作为一个二分类分类器输出二维概率,分别指示该句子属于真实的概率和属于机器生成的概率。使用强化学习中的策略梯度进行训练,最大化来自判别器的奖励期望。
-
使用 REGS(reward for every generation step)来提供及时奖励。
1. 第一种方式使用蒙特卡洛搜索来估计当前状态的价值,该方法与 SeqGAN 类似,这种方法由于采样过程需要消耗一定的时间。
2. 第二种方式为,直接训练一个判别器,可以为全部或者部分生成的句子打分,可以节省时间,但是相比于第一种方法,准确率较低。 -
使用 Teacher Forcing 的训练方式帮助训练——解决了生成器生成数据不稳定,导致判别器打分很低,就无法很好地更新生成器,导致训练无法收敛的问题。
4.2.8 MASKGAN: Better Text Generation via Filling in the _____$^{21}$¶
- 让生成器(Seq2Seq)完成类似于完形填空的任务来提高文本生成的质量,输入是隐藏掉几个词语的一句话,输出一句补全的话,希望输出的词语尽可能的与真实词语相近。
- 判别器(Seq2Seq)在训练过程中模拟采样过程——缓解在生成过程中,一但出现错误,模型会基于错误的分布继续进行生成的问题。
- 判别器输入生成器的输入与输出,并在解码器部分的每一个位置输出标量概率, 而不是在词表中进行选择。将这些概率作为奖励传递给生成器。
- 通过由 Seq2Seq 实现的判别器在每一时刻提供奖励,使得生成器的输出更加满足真实分布。
- MaskGAN 使得模型能够在词级别的生成上做判断——解决了训练不稳定和模式下降,导致生成器学习到的句子多样性较差的问题。
五、GAN、RL和VAE的概念澄清¶
5.1 GAN和RL的联系¶
说“GAN是RL的特例”有失偏颇。准确来说和GAN很相似的是Actor-Critic(AC)。更准确来说是以Deterministic Policy Gradient(DPG)为代表的对于连续动作输出建模的RL算法$^{29}$。
论文$^{30}$讨论了GAN和Actor-Critic方法的联系。
Here we show that GANs can be viewed as actor-critic methods in an environment where the actor cannot affect the reward.
详细的讨论可以参考原文。
5.2 GANs和VAE的联系$^{28}$¶
GAN和VAE都属于深度生成模型(deep generative models, DGM),二者都能够从具有简单分布的随机噪声中生成复杂分布的数据(以逼近真实数据的分布),二者的区别在于,从不同的视角看待数据的生成过程,进而构建了不同形式的损失函数来衡量生成数据的度量。
对于VAE,研究者认为数据$x$是由一个潜变量$z$生成得到的,考虑$p(x)=\int_z p(x\mid z)p(z)dz $,但由于这一目标包含高维空间的积分操作,较难优化,因此退而求其次提出$\log p(x) \ge ELBO$作为原始目标的下界,由此产生模型中的encoder和decoder结构,由于lower bound只是原likelihood的近似,所以VAE无法显式给出数据的分布;
对于GAN,研究者认为$x$的复杂分布可以从一个简单的分布$p(z)$经过一系列变换得到,在GAN中,并不要求变换是可逆的(另一类flow model则要求变换可逆(invertible)),因此,我们无法写出$p(x)$,只能得到生成数据的采样$x'=g(z),z\sim p_0(z)$。与VAE不同的是,这里的$z$仅仅是一个简单分布中采样的到随机噪声,不具有物理含义,通常无法作作为$x$的一种表示。但VAE中的潜变量(latent variable)$z$是具有物理含义的,其包含了$x$的特征和信息。
六、其他¶
文献$^{1,2,3}$系列十分适合作为GAN for text的入门材料,本文借鉴了大部分内容。
SeqGAN$^{10}$的内容比较完整,思路也比较新颖。
RelGAN$^{18}$的消融实验做的比较全面。
文献$^{27}$对受控文本生成(CTG)领域作了详细的调研。
Refs.¶
- Generative Adversarial Networks for Text Generation — Part 1
- Generative Adversarial Networks for Text Generation — Part 2: RL
- Generative Adversarial Networks for Text Generation — Part 3: non-RL methods
- 强化学习基础介绍
- f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
- wiki-相对熵
- wiki-散度
- Improved Training of Wasserstein GANs
- Categorical Reparameterization with Gumbel-Softmax
- SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
- Adversarial Text Generation Without Reinforcement Learning
- Paper with code subtask: Text generation
- categorical_distribution
- GANs for Sequences of Discrete Elements with the Gumbel-softmax Distribution
- Generating Text via Adversarial Training
- RankGAN: Adversarial Ranking for Language Generation
- Generative Adversarial Nets
- RelGAN: Relational Generative Adversarial Networks for Text Generation
- Relational recurrent neural networks
- Adversarial Learning for Neural Dialogue Generation
- MASKGAN: Better Text Generation via Filling in the _____
- LeakGAN: Long Text Generation via Adversarial Training with Leaked Information
- SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
- Generating Text through Adversarial Training using Skip-Thought Vectors
- Token Manipulation Generative Adversarial Network for Text Generation
- Contrastive Learning with Adversarial Perturbations for Conditional Text Generation
- Conditional Text Generation for Harmonious Human-Machine Interaction
- EverGlow的回答
- yulong的回答
- Connecting Generative Adversarial Networks and Actor-Critic Methods