一、文本生成概览¶
文本生成在机器翻译、Image caption、对话系统等领域有着非常广泛的应用,根据输入来源不同,文本生成可以分为以下几类:
- Text-to-Text
- Data-to-Text
- Table-to-Text
- Vision-to-Text (Image caption)
目前文本生成面临的挑战:
- 语法合理、自然流畅
- 在不同的任务中,如何对源输入进行合理抽取、简化和变换
本文重点关注文本到文本(Text-to-texts)领域,目前文本到文本的应用如下:
-
machine translation
-
fusion and summarization of related sentences or texts to make them more concise
-
simplification of complex texts
-
automatic spelling, grammar and text correction
-
automatic generation of peer reviews / stories / News
-
generation of paraphrases of input sentences
-
automatic generation of questions, for educational and other purposes
二、模型结构概览¶
目前最常用的文本生成框架是Seq2seq,除此之外,也有基于RL、VAE和GAN的文本生成相关的研究,但从研究热度、实用性和实际效果来看,Seq2seq模型仍然是目前可控文本生成的首选,本文也重点关注基于Seq2seq的模型。
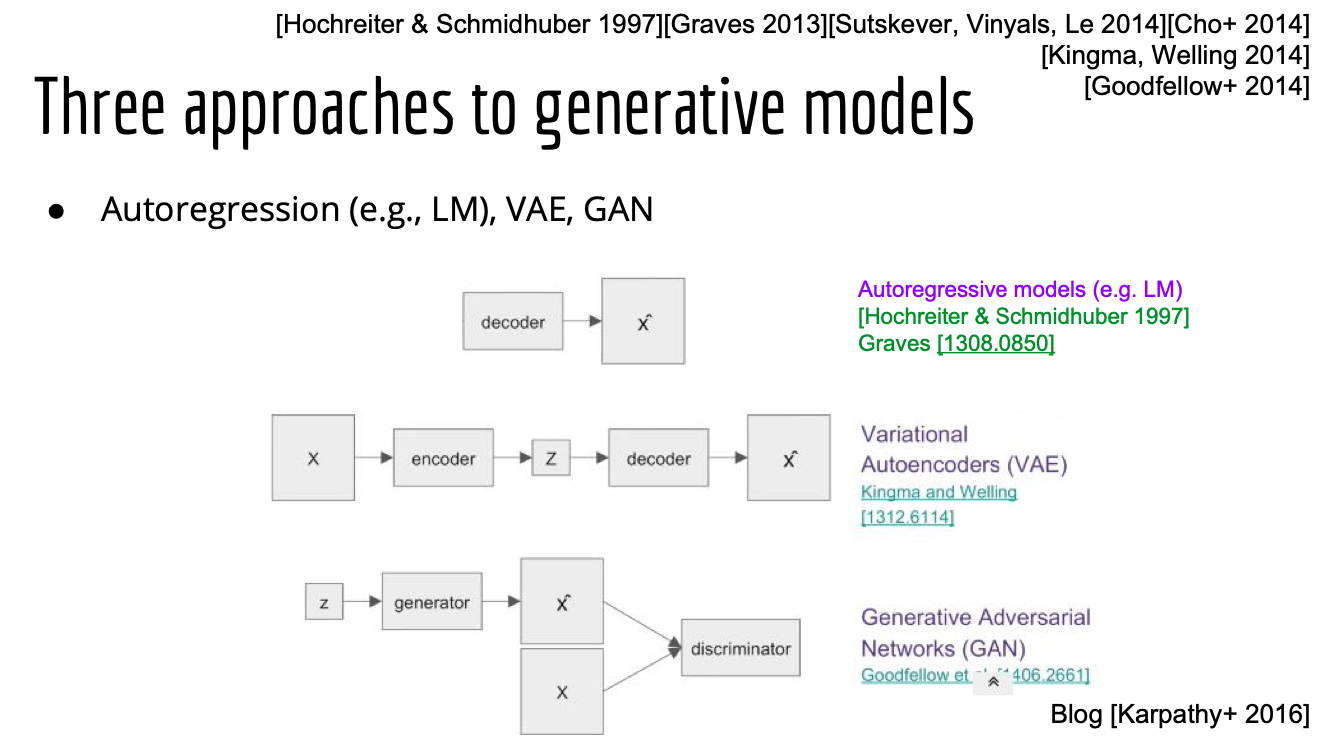
-
VAE based models
-
CVAE
- VAE-seq2seq
- 多级隐变量VAE
-
PHVM(Planning-based Hierarchical Variational Model)
-
GAN based models
-
SeqGAN
suffer from two problems:
- gradient vanishing
when the discriminator is trained to be much stronger than the generator, it becomes extremely hard for the generator to have any actual updates since any output instances of the generator will be scored as almost 0. This may cause the training stops too early before it comes to the true convergence or Nash Equilibrium.
- mode collapse
which increases the estimated probability of sampling particular to- kens earning high evaluation from the discriminator. As a result, the generator only manages to mimic a limited part of the target distribution, which significantly reduces the diversity of the outputs.
-
RL based models
-
CNN based models
-
Convolutional Sequence to Sequence Learning(FAIR)
-
Seq2seq based models
- seq2seq+attention$^{12}$
- CopyNet$^{13}$
- coverage机制
- 改进注意力$^{15}$
- seq2seq pointer generator networks$^{16}$
三、Seq2seq文本摘要研究¶
文本摘要任务有两种思路:抽取式摘要(Extractive)和生成式摘要(Abstractive),两者的特点分别是:
- 抽取式:抽出的内容合理,但行文不够流畅
- 生成式:生成内容比较流畅,但内容可控性差,易与原文产生差别
为了融合两种思路的优点,近些年有许多工作尝试了抽取+生成的方式进行摘要。下文分别选取抽取式、生成式、抽取+生成融合三种文本摘要方法中,比较典型的几篇工作,介绍目前基于seq2seq进行文本摘要的进展。
3.1 抽取式摘要¶
3.1.1 SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents$^{3}$¶
采用双层RNN,底层对每一个句子进行编码,顶层RNN对句子序列做标注,生成0/1标签,用于表示是否在摘要中选取该句子(显然,这个模型在做的是在篇章中选择重要的句子,而对于单个句子内的词,则没有进一步选择)
该模型的另一个设计是loss,可以参考如下。

3.1.2 Neural Summarization by Extracting Sentences and Words$^4$¶
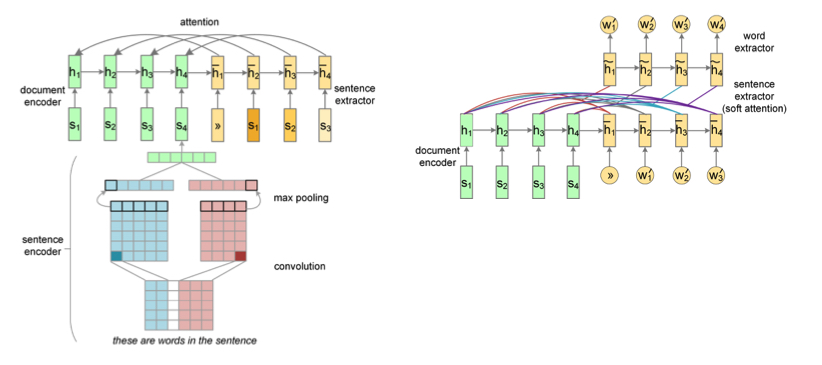
本文的文本摘要分为两个层级,首先从篇章中选择句子(Sentence extractor, SE),其次从句中选择词语(Word extractor, WE)。前者是一个序列标注任务,后者是一个文本生成的任务。
使用CNN编码句子,对于篇章中的N个句子,得到其表示后,进入RNN的encoder、decoder,得到每一个句子是否选择的结果(0/1);Word extractor类似一个生成任务,负责选择重要的成分,并将它们合理地、流畅地组织起来。WE接收SE选择的若干个sentence的表示,作为decoder的输入,直接解码得到生成summary的下一个词。WE使用hierarchical attention结构,首先计算对各个sentence embedding的attention,然后计算对sentence中每个词的attention,使用softmax得到一个词。WE可以看作一个受限词表的条件语言模型。
3.2 生成式摘要¶
3.2.1 A Neural Attention Model for Abstractive Sentence Summarization$^{12}$¶
Attention-Based Summarization,2015年提出,比较早的模型了,借鉴NMT,典型的Seq2seq+attetion的生成模型。解码词表使用全量词表。
3.2.2 Deep Recurrent Generative Decoder for Abstractive Text Summarization$^5$¶
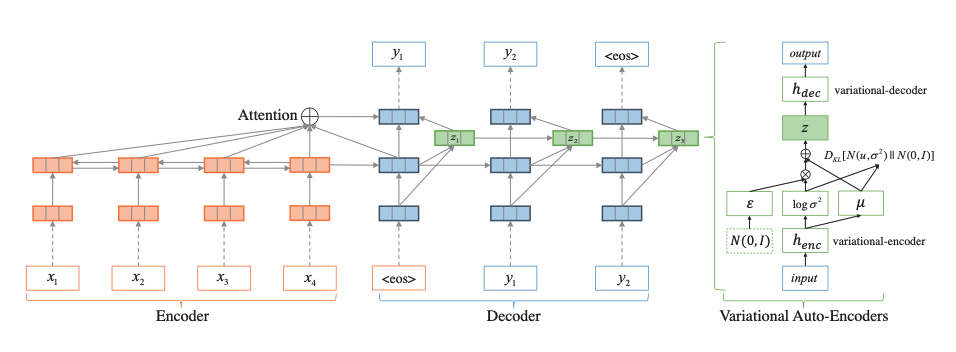
使用Seq2seq+attn结构,创新点在解码端:For latent structure modeling, we add historical dependencies on the latent variables of Variational Auto-Encoders (VAEs)。
3.2.3 Abstractive Sentence Summarization with Attentive Recurrent Neural Networks$^6$¶
embedding使用token embedding+可训练的位置embedding,encoder使用CNN(attentive),每个token得到一个编码表示$z_i$,解码使用RNN。
3.3 抽取+生成结合¶
抽取式摘要无法生成除原文本以外的词汇;而生成式摘要无法避免OOV问题,近期有很多模型尝试将二者进行融合,即在解码阶段动态地选择从原文本中”抽取式“地得到一个词,或从候选词表中”生成式“地得到一个词。
比较有代表性的工作有:
- Pointer-Generator Network(PGN)(Google+Stanford)
- CopyNet(港大+华为)
3.3.1 Get To The Point: Summarization with Pointer-Generator Networks (PGN) $^{16}$¶
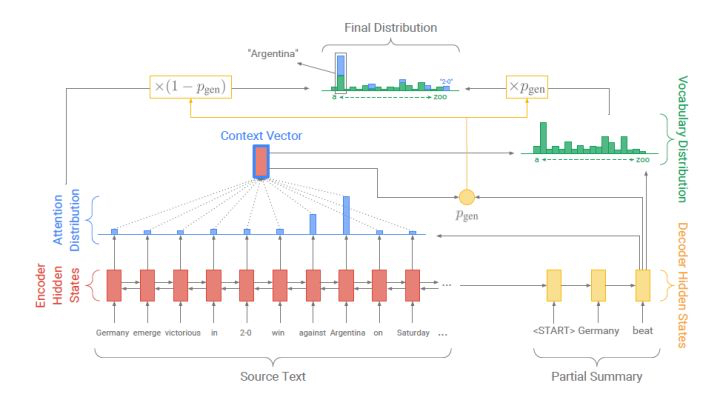
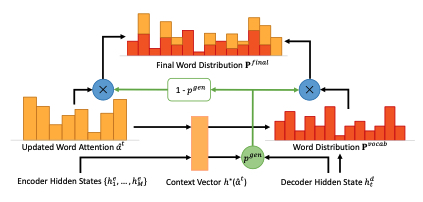
不同于传统的Seq2seq+attention模型,PGN在解码阶段生成一个概率$P_{gen}$,用于表示当前解码时间步需要从完整词表中生成一个词的概率,则1减去该概率表示从原文本中选择一个单词的概率,由于解码过程中,pointer部分可以得到原文本中每个词的选择概率,同时,解码器也能获得词表中每一个单词的生成概率,使用概率$P_{gen}$将这两个概率分布进行整合,得到最终的词汇分布概率。
3.3.2 Incorporating Copying Mechanism in Sequence-to-Sequence Learning$^{13}$¶
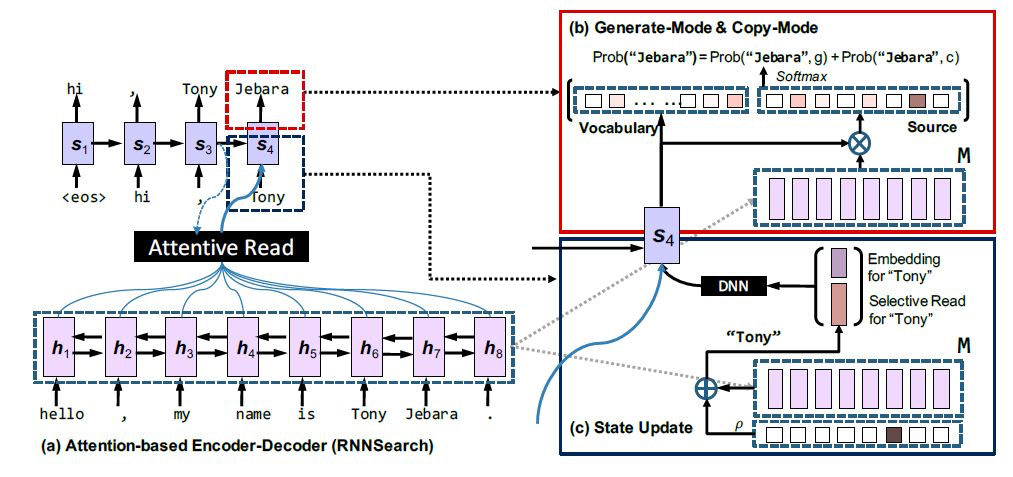
这篇文章的思路和上文的PGN比较类似,在上图右上的红框中,解码器得到的概率分布分为两部分,词表中的词汇概率分布和原文本中的词汇概率分布,PGN使用一个软概率将二者进行融合,而本文则直接地进行加和。
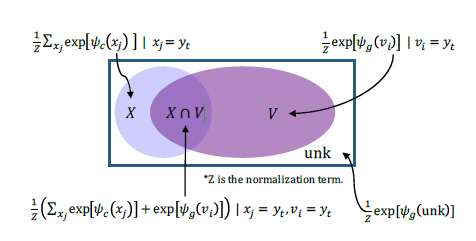
如上图,可以简单理解为:
- 如果一个词仅存在于原文本,则其来源于生成模型的概率为0,来自选择模型的概率不变
- 如果一个词仅存在于词表中,则其来源于生成模型的概率保持不变,来自选择模型的概率为0
- 如果一个词既存在于原文本中,也存在于词表中,则其生成概率为两个概率的加和
值得注意的是,生成概率和选择概率的计算方式不同:

3.3.3 A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss$^7$¶
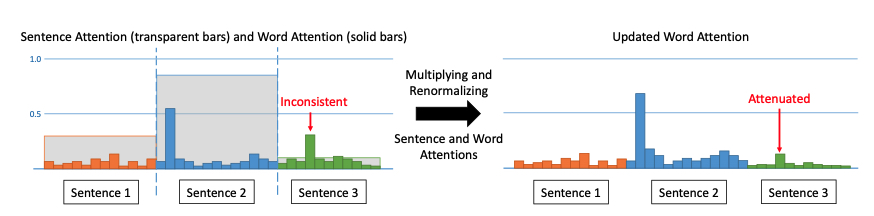
本文创新点如下:
- 两层attention:sentence level、word level,使用前者调节后者,能够达到”降低位于低注意力的句子中的单词被生成的概率“。
模型分为两部分:extractor、abstracter,二者均以单个句子为输入,extractor输出一个概率序列,表征输入句子序列被”抽取“的概率(sentence level attention)。同时,abstracter动态地计算当前句子中每个词被生成的概率。对两种attention score的聚合则是简单地进行分数相乘,然后作归一化。
- 为了消除两层attention的矛盾性(inconsistentency),引入inconsistentency loss
为了对两种attention分数作统一(consistent),这里引入inconsistentency loss:
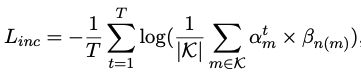
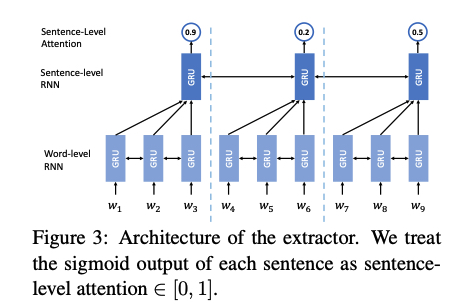
abstracter的结构和PGN是一致的。
本文同时也使用了PGN中的coverage思想:使用coverage vector来维护截至当前在每个词汇上的注意力如何,coverage vector会参与word level attention的计算,并通过coverage loss 的方式参与训练。
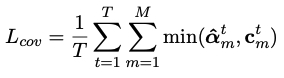
3.3.4 Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond$^{8}$¶
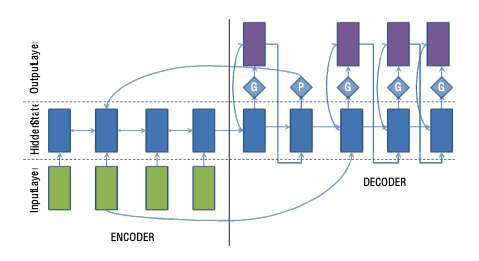
论文点:
- 使用概率控制从vocab中生成还是从原文中选择一个
- large vocabulary ‘trick’:the decoder-vocabulary of each mini-batch is restricted to words in the source documents of that batch. In addition, the most frequent words in the target dictionary are added until the vocabulary reaches a fixed size. 限制解码词表大小,优化softmax
- Feature-rich Encoder:encoder输入:词embedding+POS+NER+TF+IDF
- Hierarchical Attention to capture sentence structure
Refs.¶
- Neural Abstractive Text Summarization with Sequence-to-Sequence Models
- Text-Summarization-Papers
- SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents
- Neural Summarization by Extracting Sentences and Words
- Deep Recurrent Generative Decoder for Abstractive Text Summarization
- Abstractive Sentence Summarization with Attentive Recurrent Neural Networks
- A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss
- Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
- Neural Text Generation: Past, Present and Beyond
- Survey of the State of the Art in Natural Language Generation: Core tasks, applications
- Text Generation Survey 2017 by Ni Lao
- A Neural Attention Model for Abstractive Sentence Summarization
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning
- Extractive-abstractive summarization with pointer and coverage mechanism
- Guiding Generation for Abstractive Text Summarization based on Key Information Guide Network
- Get To The Point: Summarization with Pointer-Generator Networks