一、学习率¶
在模型训练过程中,学习率是一个非常敏感且重要的参数,在神经网络的反向传播算法中,梯度下降是一种常用的参数求解方法,学习率影响着梯度下降过程中参数更新的步长。通常,神经网络的参数空间很大,梯度下降的求解目标是最小化定义在参数空间中的损失函数$L$,由于参数维度很大,目标函数一般包含着许多局部最小值点(现有的研究证明,局部极小值已经不是影响神经网络效果的最大障碍了,也即,即使我们找不到全局最小值,一个好的优化算法一般总能找到一个“足够好”的局部极小值)。学习率的影响体现在,如果学习率过小,则参数大小更新的速度会很慢,如果在训练开始前,参数没有被很好地初始化,小的学习率很有可能使目标函数陷入一个并不足够好的局部极小值点而无法跳出;相反,如果学习率设置很大,一方面参数更新的幅度很大,对应的目标函数很有可能在参数空间中反复跳动,即使在迭代过程中,模型寻找到了一个足够好的参数组合,较大的更新幅度也会导致有可能在下次迭代中跳出,导致训练过程的不稳定,训练中表现为训练集损失函数波动明显,收敛困难。
针对学习率的优化有以下几个方面:
- 基础学习率的设定
一般使用一个区间内的学习率,在一个epoch中,学习率由最小逐渐增加到最大,观察损失函数的变化情况,一般情况下,我们要寻找的合理的学习率区间内的损失函数应具有较高的下降速率。
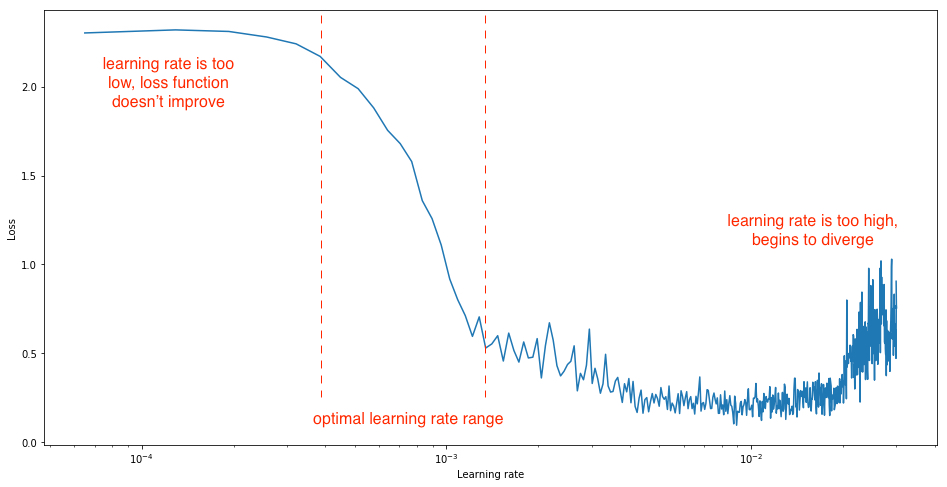
- 训练过程中的学习率调整
一般的调整方式有:
- 初期学习率warmup:训练初期,学习率有一个比较小的值逐渐增加到基础学习率;
- 学习率衰减:训练过程中,学习率以某种衰减曲线形式逐渐减少;
- 循环学习率(Cyclical learning rates):随着训练过程进行,学习率以循环的方式,逐渐增加至基础学习率,然后逐渐衰减到一个较小值,这个过程循环执行,直至训练结束,过程中,基础学习率本身可能也会以某种方式逐渐衰减。
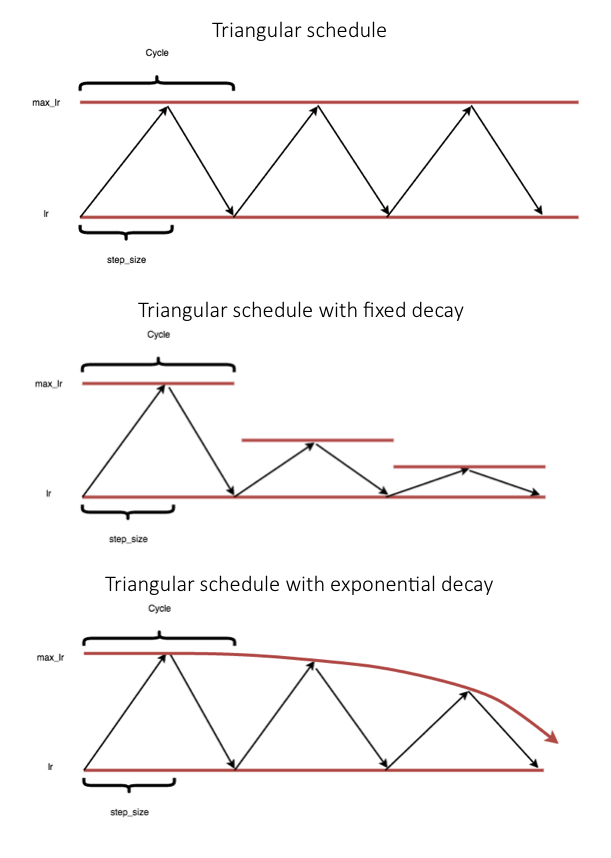
与训练过程中,学习率一直下降相比,学习率在训练过程中增加的一个理论假设是,“短期内,增加学习率会导致损失增加,但长期来看,模型会收敛到一个更优的解”。支撑这一假设的两个偏直觉性的推断是:
-
从训练目标来看,我们希望训练的到的参数足够鲁棒,也即输入或参数微小的波动不应该导致目标函数/损失函数发生大幅度的变化,这种变化尤其可能发生在比较狭小的极小值处(sharp minima lead to poor generalization,后文讨论batch size的影响时会提到),训练过程中增加学习率,能够有更大的可能使参数从这种不理想的极小值出跳出;
-
同样的,目标函数表面可能存在非常多的鞍点(在某些参数维度上,目标函数取极小值,同时,在其他参数维度上则取最大值),训练过程中增加学习率有助于更快地脱离鞍点,起到加快收敛的作用。
训练神经网络基本等价于对一个高维非凸函数求最值的问题,这个问题理论上非常困难,但实践中有时又比较简单:在一些简单的任务上,基于梯度下降算法的优化方法总能寻找到全局最优解。但这并不总能实现,神经网络的可训练性受到网络结构设计、优化器的选择、参数的初始化效果、训练数据分布和其它一些因素的共同影响,针对这些因素,实践中没有一套通用的准则来指导。某些特定的网络结构能够使得训练过程更为容易(如skip connections等),这篇文章Visualizing the Loss Landscape of Neural Nets 通过可视化的手段分析了神经网络损失函数的结构,概括性分析了这些结构对于训练的影响,以及参数对训练过程的影响。作者发现,随着网络深度的增加,损失函数的非凸性加剧。
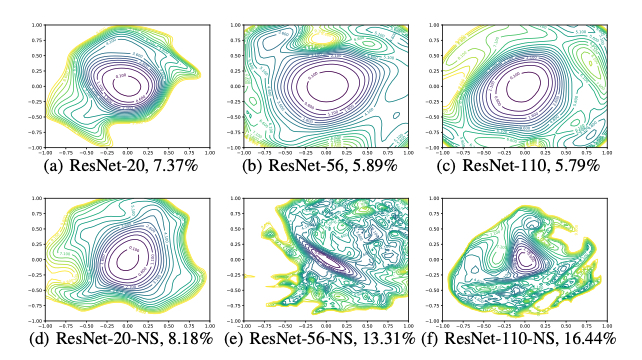
并通过实验发现,如果在网络中加入一些短路连接,则损失函数表面则倾向于变得光滑。
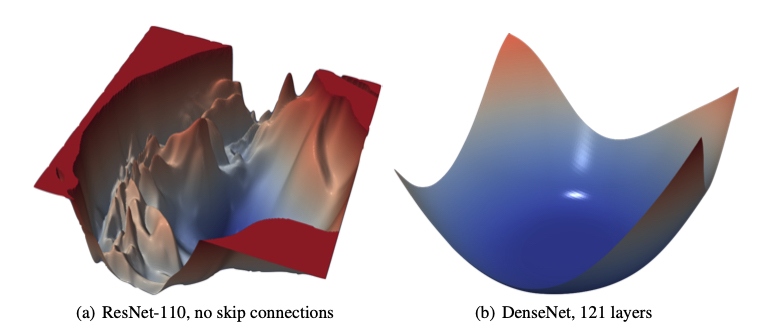
这篇文章Essentially No Barriers in Neural Network Energy Landscape 证明了,在较大的神经网络中,全局最优解往往不是一个点,而是一个连通的流形(manifold),一个更一般化的说法:如果目标函数存在两个局部最优解,则一定可以通过一条平坦的路径(flat path),使得这两点连通。
二、Batch size¶
在神经网络训练过程中,另一个比较重要的超参数是batch size,为了使每次迭代的计算量是可承受的,我们将所有的训练数据划分为许多个mini-batch,同时为了更充分地利用并行化的优势,应在设备允许的范围内尽量大地设置batch size,人们在实践中发现,增大batch size后,模型在测试集上的表现往往会变差,在ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA 的实验中,由batch size变化带来的性能差距甚至能够达到5%。针对此现象,可能的解释如下:
- batch size增大时,模型倾向于过拟合
- batch size增大时,优化过程中更有可能遇到鞍点
- 与小batch size训练出的模型相比,大batch size模型在优化过程中缺乏探索性,以致倾向收敛于距初始参数较近的局部最优解
- batch size变化时,模型收敛到的最优解具有不同的泛化特性
作者通过统计性实验证明了后两个推论的合理性:增大batch size时,模型倾向于收敛到尖锐的局部最小值处,该处表现为矩阵$\nabla ^2 f$的正特征值更大;相反地,对于较为平坦的局部最小值处对应的$\nabla ^2 f$的特征值则会小得多。 作者强调,由于batch size变化造成的泛化能力差别(generalization gap)并不是由过拟合引起的。
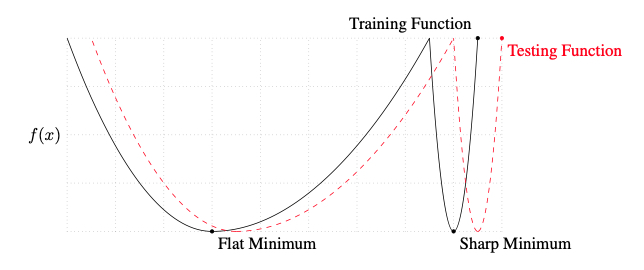
在大型网络中,计算$\nabla ^2 f$的特征值来表征极值点处的尖锐程度的代价十分高昂,因此作者提出了一种替代方案用于表征目标函数任一点处的尖锐程度,并通过实验对比了batch size变化时,目标函数尖锐程度的变化情况:
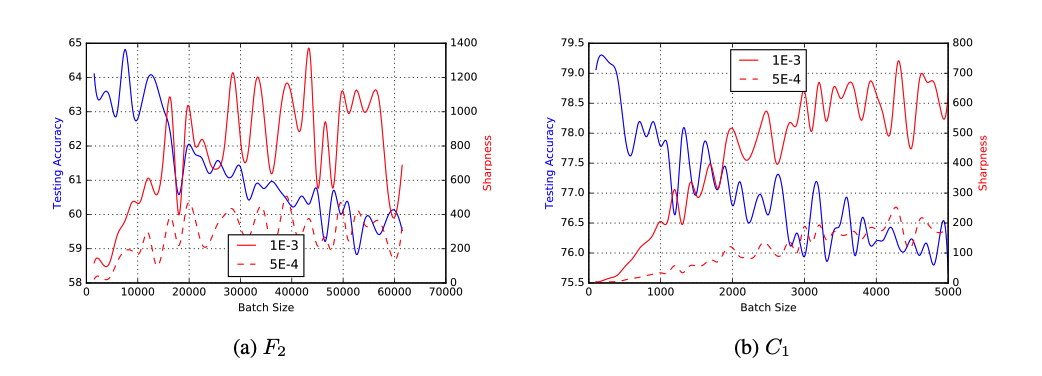
为了尝试解决大batch size遇到的问题,作者尝试了数据扩增、使用更加鲁棒的优化器等措施,但实验证明,在较大的batch size下,这些方法仍倾向于收敛到sharp minimizers上,另一种使得大batch size可行的方案是,使用小batch size先进行warmup,然后再将其调整到预设的batch size。
另外几个有意思的问题:
- 我们可以证明大的batch size总是会导致深度神经网络收敛到更尖锐的局部最小值吗?
- 在神经网络中,尖锐程度不同的局部最小值的密度分布情况时怎样的?
- 我们可以设计出适合大batch size的神经网络结构吗?
- 是否能够寻找到一种良好的初始化方法,使得大batch size可以应用在普通的神经网络上?
- 是否能够通过算法或者正则化手段,使得能够避开sharp minimizers?
Refs.¶
Recent Advances for a Better Understanding of Deep Learning − Part I
Setting the learning rate of your neural network
Visualizing the Loss Landscape of Neural Nets
Essentially No Barriers in Neural Network Energy Landscape
ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA