多模态学习旨在搭建能够处理多种模态信息的模型,文章Multimodal Machine Learning: A Survey and Taxonomy 从表示(Representation)、翻译(Translate)、对齐(Alignment)、融合(Fusion)、协同学习(Co-learning)等几个方面对多模态学习进行综述。重点关注语言、图像和声音三种模态。
- 表示(representation):各种模态是异质的(如文本通常基于符号表示,而声学和视觉信息往往通过信号表示),构造使得不同模态信息能够互相融合、摒弃冗余信息的信息表达方式是至关重要的。
- 翻译(translation):多种模态之间的对应关系开放性、主观性较强,模态间的映射常常不止一种方式,思考:用一段话描述一张图片,有几种方式?
- 对齐(alignment):模态间的信息需要进行对其,用以确定不同模态内的元素的直接关系
- 融合(fusion):在实际运用中,应寻找合理的多模态信息融合方式,以最大化多模态共同预测时的效率和准确率
- 协同学习(co-learning):在某一种模态资源有限时,通过资源丰富的另一种模态辅助训练,以达到多个模态的模块协同训练的目的。
一、多模态模型的应用历史¶
- AVSR:(Audio-visual speech recognition):原本意在通过视觉信息提高语言识别准确率,实验发现视觉信息在语音信息包含噪声较多时变得重要,这一试验表明视觉信息和语音信息这两种模态之间有一定的信息交互;
- 多媒体信息检索:互联网上各种模态信息增长趋势迅猛,需要开发能够直接进行多模态信息检索的模型,来逐渐取代单纯的基于关键词的信息检索方式。一个优秀的数据集:MED(multimedia event detection);
- 人类多模态交互理解:21世纪初逐渐兴起,数据集有:AMI Meeting Corpus 、SEMAINE corpus,比赛:AVEC challenge;
- 最近兴起了语言和视觉两种模态融合的任务,如image captioning(图像描述),这一任务的难点在于模型的评价,VQA任务通过图片提问的方式尝试解决这个问题。
二、多模态学习的表示问题(representations)¶
多模态表达面临以下几个问题:如何融合多种模态的特征?如何处理不同层级的噪声?如何处理缺失的模态?Bengio认为,一个好的表示,应具有以下特点:平滑性(smoothness),时空一致性(temporal and spatial coherence),稀疏性(sparsity),聚集性(natural clustering amongst others);至于多模态表达,Srivastava and Salakhutdinov提出,表示空间中的相似表达应能够反映不同模态所包含的概念的相似程度;多模态的表征应是易于获取的,即便某些模态数据缺失,并且,其余模态数据应能够“推理”出缺失模态的表达。
至3
三、论文笔记¶
多模态学习是目前深度学习领域中一个比较热门的方向,这里记录一下这个方向的相关论文。
3.1 One model to learn them all (2017)¶
本文提出了一个多模态模型,将8个任务融合在一个模型中,具体包含:
- Parsing
- Speech recognization
- ImageNet classification
- Image caption
- Translation
模型在各个任务上都取得了不错的效果,部分超过了一些新模型(虽然还没有达到sota水平)。
作者认为,本文有两个主要贡献(对多模态网络至关重要的两点):
- 信息通过各个模态相关的小型网络转换到一个通用的中间形态,再由该中间形态通过不同的模态网络转化为输出
- 中间表示层的尺度是可变的
- 同一领域下,不同任务共享模态网络 - 各种任务对各个子计算模块的重要性依赖程度不同(如,attention机制在翻译任务中的重要程度高于其在image caption任务中的影响)
3.1.1 模型结构¶
模型的整体结构分为三部分:
- encoder
- I/O Mixer
- AR decoder
在encoder和decoder中,主要包含以下计算组件(computational blocks):
- conv
局部特征捕获,使用depthwise separable conv
- attention layer
关注重要的特征
- 稀疏门限模块集成(Sparsely-gated mixture-of-experts)
在保证计算复杂度的前提下,增大模型容量,由一系列前馈网络和可训练的门限网络构成,负责从各个输入中选择稀疏的组合
为了适应各个任务的形态,本文提出了一些任务相关的子网络(模态网络,Modality-nets),主要包括:
- 语言模态网络
- 图像模态网络
- 类别模态网络(Categorical modality net)
- 语音模态网络
3.1.2 实验部分¶
实验部分,本文回答了三个问题:
- 本文提出的MultiModel在8个子任务上,离sota还有多远?
看论文结果,应该还是有一段距离,作者表示由于没有仔细调参,当前多模态模型的结果还无法超越经过细致调参的传统模型。
- 同时训练8个子任务,与分别训练有什么差别?
在训练多模态模型的同时 ,作者在同等条件下同时训练了独立的模型,实验结果表明多模态联合训练时的结果与独立训练各个任务相似,在个别任务上甚至有一些提升,训练数据越少的任务,提升通常会越明显。
- 不同的计算组件(computational blocks)在子任务上的影响如何?
这些组件的存在,至少不会带来子任务性能的下降。
多模态网络设计的要点在于,任务间能够共享的参数尽量要在模态间共享,这有助于不同模态之间表示空间的统一,同时也能降低task-specific的参数量,控制模型的尺寸。
3.2 UniT: Multimodal Multitask Learning with a Unified Transformer (2021)¶
在Transformer提出后,其应用场景可以大概分为下面几类:
- 在单领域或者特定场景下的多模态领域,如:
- VIT和DETR关注视觉任务
- BERT及变体关注语言任务
- VisualBERT、VILBERT关注特定领域内的语言、视觉多模态任务
- 引入任务相关的微调机制(finetune),如BERT应用于语言任务时,需要针对每个下游任务重新微调
- 在特定场景中的相近或相似任务中引入多任务学习(有时也加入一些特定的训练技巧)
也就是说,目前还没有一个能够在通用领域下的基于Transformer的多模态模型,我们不禁要问:
Is it possible to build a single model that simultaneously handles tasks in a variety of domains as a step towards general intelligence?
本文提出了UniT(Unified transformer encoder decoder architecture),使用更少的参数量完成多领域(multiple domain)下多任务(multiple task)的学习。具体任务如下:
- 目标检测(object detection)
- 视觉问答(visual question answering)
- 视觉蕴含推理(visual entailment)
- 自然语言理解(NLU)
- QNLI
- MNLI
- QQP
- SST-2
在基于transformer的多任务学习领域,目前已经有不少研究,其中大部分关注特定领域/模态,由于transformer结构适应性比较强,可以用于文本分类、机器翻译、图像描述等任务,在以往的研究中,不同的任务往往会设计不同的decoder参与finetune,而本文提出的UniT的一大特点是,尝试通过相同的decoder模块/参数来进行所有任务的学习。
具体地,UniT使用了两类encoder,分别负责文本和图像的编码,在获得两类输入的编码后,通过拼接的方式作为Multi-Head Cross Attention的Key和Query向量输入decoder;同时,decoder接收任务相关的query embedding作为输入;decoder的输出经过不同的head,进入各个子任务的学习。模型结构图如下:
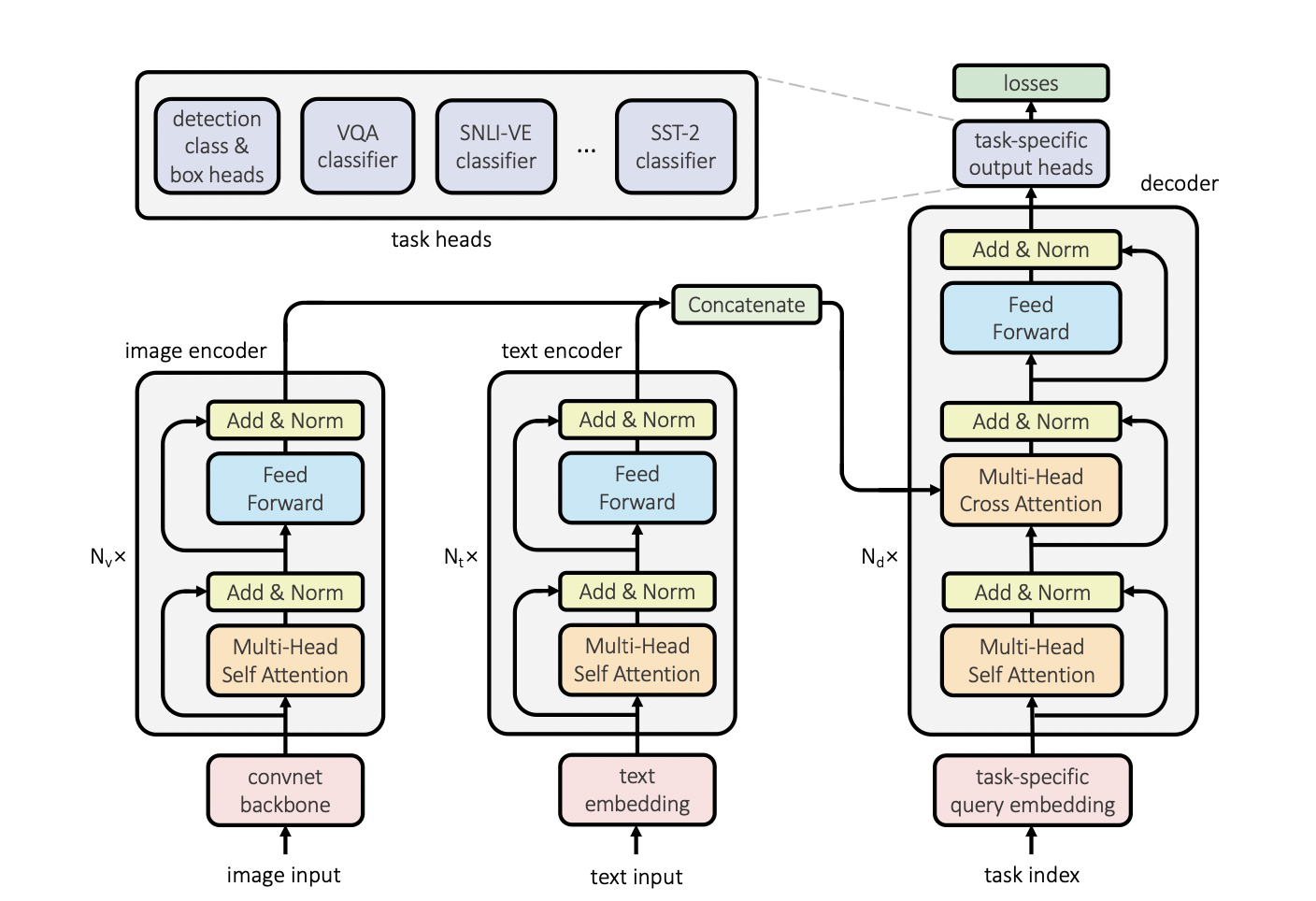
Refs: